本着 Learning by teaching 的原则,结合目前自己的一些现代 C++ 实践,小小记录一下。能力所限,本文不可避免地会有考虑不周的地方,还请大家多多指正🤣。
类型推导
突击检查:
char const *(*(* const bar)[5]) (int)是什么类型?
不过我们今天的主题不是做类型体操,而是讨论一下在引入 auto 、 decltype 等关键字后,C++ 的类型推导主要分为哪些,如何进行。
模板类型推导
C++ 函数模板的使用可归结为以下形式:
// 声明
template <T>
void f(ParamType param); // 其中 ParamType 为包含 T 的组合类型
// 调用
f(expr);
例如对于以下函数模板和调用语句:
template <T>
void f(const T ¶m);
int x = 0x114;
f(x);
T 将被推导为 int , ParamType 则为 const T & 。
这个简单的例子可能会让我们误以为 T 的类型仅依赖 expr ,实际上并非如此, T 的类型推导结果还依赖于 ParamType 的形式,可总结为以下三种情况。
一、 ParamType 是个指针或引用(但不是万能引用)
这种情况下,类型推导过程遵循以下原则:
expr的 reference-ness 会被忽略:引用的引用还是引用(想起了阿尼亚的表情包)expr的 constness 会被保留:当函数的形参为引用类型时,调用者肯定不希望原本为const的常量在调用后被修改了
举个例子,
template<typename T>
void f(T ¶m); // ParamType 为 T&
int x = 0x114;
const int cx = x;
const int &rx = x;
f(x); // T -> int, ParamType -> int&
f(cx); // T -> const int, ParamType -> const int&
f(rx); // T -> const int, ParamType -> const int&
对于原则二,如果 ParamType 本来就是 const 引用类型,此时 T 就没必要推导为 const 类型了,例如
template<typename T>
void f(const T ¶m);
int y = 0x514;
const int cy = y;
f(cy); // T -> int, ParamType -> const int&
对于指针,也是一样的推导过程。
二、 ParamType 是个万能引用
C++11 引入右值引用时,也引入了万能引用(Universal reference named by Scott Meyers,我自己更倾向于理解为“发生类型推导前夕的右值引用”)。这种情况下,类型推导过程遵循引用折叠(Reference collapsing)的原则:
如果
expr为左值,T和ParamType会被推导为左值引用(这是在模板类型推导中,T被推导为引用类型的唯一情形)如果
expr为右值,则复用上面的第一种情况
例如:
template <typename T>
void f(T &¶m);
int x = 0x114;
const int cx = x;
const int &rx = x;
f(x); // x -> lvalue => T -> int&, ParamType -> int&
f(cx); // cx -> lvalue => T -> const int&, ParamType -> const int& && -> const int &
f(rx); // rx -> lvalue => T -> const int&, ParamType -> const int& && -> const int &
f(0x514); // 0x514 -> rvalue => T -> int, ParamType -> int&&
三、 ParamType 既非指针也非引用
这种情况下,top-level CV 类型限定符会被忽略,但注意 low-level 的 constness 将被保留。
template<typename T>
void f(T param);
const char * const ptr = "Hello world";
f(ptr); // 修饰 ptr 本身的 const 被忽略,修饰 ptr 指向对象的 const 被保留
// 因此 T, ParamType 均被推导为 const char *
另外,数组和函数在 ParamType 为值类型时会分别退化成指针和函数指针,例如:
template<typename T>
void f(T param);
template<typename T>
void f_ref(T ¶m);
const char name[] = "Hello world";
f(name); // ParamType -> const char *
f_ref(name); // ParamType -> const char (&)[12]
void func(int);
f(func); // ParamType -> void (*)(int)
f_ref(func); // ParamType -> void (&)(int)
auto 类型推导
auto 的类型推导与模板基本相同,唯一的差异在于它们对于 std::initializer_list 的类型推导逻辑不同。
auto x = { 0x11, 0x45, 0x14 }; // x -> std::initializer_list
template<typename T>
void f(T param);
f({ 0x11, 0x45, 0x14 }); // Compile error,类型推导失败
template<typename T>
void f2(std::initializer_list<T> param);
f2({ 0x11, 0x45, 0x14 }); // T -> int, ParamType -> std::initializer_list<int>
auto create_list() { // auto 在 C++14 中可用于说明函数返回值需要推导
return {1, 2, 3}; // Compile error,此时使用模板类型推导,而不是 auto 类型推导
}
除此之外,在 C++ 14 的某些场景, auto 关键字用于进行模板类型推导而不是 auto 类型推导(与其实现有关,比如此时 lambda 表达式会生成一个重载调用操作符的匿名模板类,因此用的是模板类型推导)
// auto 在 C++14 中可用于说明函数返回值需要推导
auto create_list() {
return { 0x11, 0x45, 0x14 }; // Compile error,此时使用模板类型推导,而不是 auto 类型推导
}
// auto 在 C++14 中可用于形参推导
std::vector<int> x;
auto reset_x = [&x](const auto& v) { x = v; }
reset_x({ 0x11, 0x45, 0x14 }); // Compile error
decltype 类型推导
decltype 进行的是一种很新的类型推导 —— 不推导,是的,只是原汁原味地返回变量的类型。
不过需要注意的是,如果 decltype 应用于一个变量 x (类型为 T )的复杂左值表达式(复杂只不止由 x 构成),将返回 T& ,否则就返回 T ,所以会出现以下这种”量变产生质变“的现象:
int x = 0;
decltype(x) // -> int
decltype((x)) // -> int &
下面是关于 decltype 的一些类型推导结果,可以上 godbolt 自己试试(包含以下代码片段)。
class Clazz {};
Clazz c1; // c1 -> Clazz
const Clazz &c2 = c1; // c2 -> const Clazz &
auto c3 = c2; // c3 -> Clazz
decltype(c2) c4 = c2; // c4 -> const Clazz &
decltype(auto) c5 = c2; // c5 -> const Clazz &
// decltype(auto) 就是 decltype + auto ^_^
// 好处是让 decltype 不再依赖形参了,很实用的一个特性
一些有用的工具
1. Boost.TypeIndex → 打印变量的完整类型(godbolt)
#include <boost/type_index.hpp>
using boost::typeindex::type_id_with_cvr;
class Clazz {};
Clazz c1;
cout << "c1 -> " << type_id_with_cvr<decltype(c1)>().pretty_name() << endl;
2. cdecl.org → 用自然语言解释变量类型
所以前面突击检查的问题,答案在这里(你做对了吗 🤣)
右值引用、移动语义与完美转发
template<typename T> void f(std::vector<T> && param);中的&&是万能引用吗?
&& : 右值引用与万能引用
在 C++11 中,
&&既可以表示右值引用,又能表示万能引用(如果你还不太清楚什么是左值/右值/纯右值,什么是右值引用/万能引用,可以参考这篇文章 ^_^)右值引用用于延长临时(将亡)变量的生命周期,常用于移动构造、移动赋值等场景,避免冗余复制操作带来的性能损耗
值得益于 RVO(返回值优化),很多情况下我们没有必要使用右值引用来优化代码,比如以下例子中,
GetClazz函数将在返回的地址上直接初始化,所以对局部变量c使用 move 是多余的,还会产生一次移动的多余开销struct Clazz {};Clazz GetClazz() {Clazz c;return std::move(c); // Badreturn c; // Good, RVO}int main() {Clazz &&c1 = GetClazz(); // Not necessaryClazz c2 = GetClazz(); // Good}&&表示万能引用的条件:具备T&&形式,且需要经过推导才能确定最终引用类型template<typename T>void f(T &¶m); // 万能引用template<typename T>void f(std::vector<T> && param); // 并非 T 本身需要推导,因为 && 表示右值引用Clazz &&c1 = Clazz(); // 右值引用auto &&c2 = c1; // 万能引用引用折叠
- 左值引用短路右值引用
// https://en.cppreference.com/w/cpp/language/reference#Reference_collapsingtypedef int& lref;typedef int&& rref;int n;lref& r1 = n; // type of r1 is int&lref&& r2 = n; // type of r2 is int&rref& r3 = n; // type of r3 is int&rref&& r4 = 1; // type of r4 is int&&- 引用折叠发生的四种场景
- 模板实例化
auto变量的类型推导- 生成和使用
typedef/using声明 decltype
std::move 与 std::forward
std::move 不进行任何移动, std::forward 也不进行任何转发,两者在运行期都不发挥作用,只是进行强制类型转换,以下是两者的简单实现。
// std::move
template<typename T>
remove_reference_t<T>&& move(T &&t) {
return static_cast<remove_reference_t<T>&&>(t);
}
// std::forward
template<typename T>
T&& forward<remove_reference_t<T> &t) {
return static_cast<T&&>(t);
}
template<typename T>
T&& forward<remove_reference_t<T> &&t) {
return static_cast<T&&>(t);
}
完美转发失效的场景
大括号初始化 由于形参未声明为
std::initializer_list,编译器会被禁止在fwd的调用过程中从表达式{1, 2, 3}出发来推导类型,所以编译器拒绝这个调用// https://godbolt.org/z/d45Wr54Yavoid f(const std::vector<int> &v) {}template<typename T>void fwd(T &¶m) {f(std::forward<T>(param));}template<typename... Ts>void fwd(Ts&&... params) {f(std::forward<Ts>(params)...);}int main() {fwd({1, 2, 3}); // Compile error// note: candidate template ignored: couldn't infer template argument 'T'// note: candidate template ignored: substitution failure:// deduced incomplete pack <(no value)> for template parameter 'Ts'auto list = {1, 2, 3}; // list -> std::initializer_listfwd(list); // OK}仅有声明的整型 static const 成员变量 编译器会对类中的整型 static const 成员变量做优化,将其编译成编译期常量,进而避免为这些成员变量分配内存;在这种情况下,对这些成员变量实施取址操作就会产生链接期间失败,解决办法是给
Clazz::kConstMember提供显式定义(只需要在类声明外边提供定义即可:const std::size_t Clazz::kConstMember;)// https://godbolt.org/z/3bqoeWsT6class Clazz {public:static const std::size_t kConstMember = 0x114514;};std::vector<int> data;data.reserve(Clazz::kConstMember); // 无法取值// 同样地,将 Clazz::kConstMember 传入 fwd,也会因为无法取址而产生链接期失败fwd(Clazz::kConstMember); // undefined reference to `Clazz::kConstMember'重载的函数名称和模板名称 函数模板没有关于类型需求的信息,因为编译器不能决议需要传递哪个函数的重载版本(跟场景一有点相似)
void f(int (*pf)(int));void f(int pf(int));int process_val(int value);int process_val(int value, int priority);f(process_val); // OKfwd(process_val); // Compiler error位域 由于位域不能对其直接取值,而函数模板的形参是个引用,因此位域不能作为其实参(但可以先将位域转换为其他类型再调用函数模板)
智能指针
智能指针是 RAII (Resource Aequisition Is Initialization) 在内存资源管理上的体现,相比裸指针需要手动管理内存的获取和释放,更加安全和易用。
auto_ptr
auto_ptr 是 C++98 残留下来的弃用特性,是对智能指针进行标准化的尝试,由于历史原因, auto_ptr 使用复制操作来移动对象,导致了一些语义上的缺陷(比如对 auto_ptr 执行复制操作会将其值置空),后来被 unique_ptr 代替。
unique_ptr
unique_ptr相比裸指针在默认情况下大小相同,性能相比shared_ptr更好,应该优先考虑选择unique_ptr来管理内存unique_ptr是典型的只可移动的对象,移动一个unique_ptr将会发生内存所有权(实际上就是其持有的裸指针)的转移unique_ptr的一个常见用法是作为工厂函数的返回类型class Animal {};class Dog : public Animal {};class Cat : public Animal {};class Pig : public Animal {};unique_ptr<Animal> produce_animal(...) {if (...) {return make_unique<Dog>(...);}if (...) {return make_unique<Cat>(...);}// ...}unique_ptr共分为两种形式,unique_ptr<T>和unique_ptr<T[]>;前者不提供索引运算符[],后者不提供*和->unique_ptr还可以传入一个自定义的析构器unique_ptr<class T, class Deleter>,但一般不需要用到(传入自定义析构器之后,unique_ptr类的大小就需要加上自定义析构器的大小了unique_ptr的一个简单实现template<typename T>class my_unique_ptr {public:my_unique_ptr() : ptr(nullptr) {}my_unique_ptr(T *ptr) : ptr(ptr) {}~my_unique_ptr() {__cleanup__();}// copying is not permittedmy_unique_ptr(const my_unique_ptr &ptr) = delete;my_unique_ptr &operator=(const my_unique_ptr &ptr) = delete;my_unique_ptr(my_unique_ptr &&another) {ptr = another.ptr;another.ptr = nullptr;}my_unique_ptr &operator=(my_unique_ptr &&another) {__cleanup__();ptr = another.ptr;another.ptr = nullptr;}// dereferencingT *operator->() const {return ptr;}// dereferencingT &operator*() const {return *ptr;}private:void __cleanup__() {if (ptr != nullptr) {delete ptr;}}T *ptr;};
shared_ptr
shared_ptr用于多个指针需要共同管理一个内存对象的情形(使用的时候,考虑一下自己是否真的处于这种情况)shared_ptr的原理是引用计数 + 共享内存- 除了持有裸指针外,还通过一个控制块来管理引用计数等信息(还有弱计数、自定义 Deleter 等,但一般情况下知道有个引用计数也就够啦)
- 指涉到同一内存对象的
shared_ptr共享控制块信息;因此,引用计数的递增和递减必须是原子操作 - 当最后一个持有某对象的
shared_ptr不再持有它时(引用计数为 0,例如shared_ptr被析构、或 reset 为另一个对象),shared_ptr会析构该对象
shared_ptr也支持指定自定义析构器,但并不作为shared_ptr类型的一部分shared_ptr<Clazz> sp(new Clazz, custom_deleter);(这一点与unique_ptr不太一样)以下情况构造
shared_ptr会创建一个控制块- 调用
make_shared时 - 从
unique_ptr/auto_ptr/ 裸指针出发构造一个shared_ptr时 - 避免从同一个裸指针出发构造多个
shared_ptr
- 调用
shared_ptr的一个简单实现
typedef unsigned int uint;
template<typename T>
class my_shared_ptr {
public:
my_shared_ptr() : ptr(nullptr), ref_count(new uint(0)) {}
my_shared_ptr(T *ptr) : ptr(ptr), ref_count(new uint(1)) {}
~my_shared_ptr() {
__cleanup__();
}
my_shared_ptr(const my_shared_ptr &another) {
ptr = another.ptr;
ref_count = another.ref_count;
if (another.ptr != nullptr) {
(*ref_count)++;
}
}
my_shared_ptr &operator=(const my_shared_ptr &another) {
__cleanup__();
ptr = another.ptr;
ref_count = another.ref_count;
if (another.ptr != nullptr) {
(*ref_count)++;
}
}
my_shared_ptr(my_shared_ptr &&another) {
ptr = another.ptr;
ref_count = another.ref_count;
another.ref_count = nullptr;
another.ptr = nullptr;
}
my_shared_ptr &operator=(my_shared_ptr &&another) {
__cleanup__();
ptr = another.ptr;
ref_count = another.ref_count;
another.ref_count = nullptr;
another.ptr = nullptr;
}
T *operator->() const {
return ptr;
}
T &operator*() const {
return *ptr;
}
uint get_count() const {
return *ref_count;
}
T *get() const {
return ptr;
}
private:
void __cleanup__() {
(*ref_count)--;
if (*ref_count == 0) {
if (ptr != nullptr) {
delete ptr;
}
delete ref_count;
}
}
T *ptr = nullptr;
// `ref_count` should be pointer pointing to heap memory,
// to share reference count between different `shared_ptr` objects
uint *ref_count = nullptr;
};
weak_ptr
引用计数的缺点是,对于循环引用,需要引入一个第三者来破局,
weak_ptr它来了weak_ptr一般通过shared_ptr创建,但不影响持有该对象的引用计数(不过会影响弱引用计数)// https://godbolt.org/z/9scTG96ssauto sp = std::make_shared<Clazz>(); // ref_count = 1std::weak_ptr<Clazz> wp(sp); // ref_count = 1sp = nullptr; // ref_count = 0, `wp` is danglingassert(wp.expired()); // passweak_ptr没有取址操作,因此如果需要取出其指向的对象,需要先通过std::weak_ptr::lock转换为shared_ptrstd::shared_ptr<Clazz> sp1 = wp.lock(); // 若 wp 失效,则返回空std::shared_ptr<Clazz> sp2(wp); // 若 wp 失效,则抛出 std::bad_weak_ptr 异常weak_ptr一般用于判断缓存失效、观察者模式、解除循环引用等场景
优先使用 make_unique 和 make_shared
make_shared 在 C++11 引入标准库,但 make_unique 在 C++14 才引入。
使用 make_unique / make_shared 的优势
性能更好(经典的两次内存分配问题)
std::shared_ptr<Clazz> sp1(new Clazz);// 两次内存分配// 1. 为 Clazz 进行一个内存分配// 2. 为 shared_ptr 的控制块进行一次内存分配auto sp2 = std::make_shared<Clazz>();// 一次内存分配// make_shared 会分配单块(single_chunck)内存,// 既保存 Clazz 对象又保存控制块对象可以避免代码异常引起的内存泄露
process_object(std::shared_ptr<Clazz>(new Clazz), do_stuff_in_danger());// 考虑以下的事件发生顺序// 1. new Clazz, 在堆上创建 Clazz 对象// 2. 执行 do_stuff_in_danger// 3. 执行 std::shared_ptr 构造函数// 其中,do_stuff_in_danger 可能在运行期产生异常,这时候就会造成// 第一步动态分配的 Clazz 内存泄露使用 make 系列函数可以让代码更简洁
auto up1(std::make_unique<Clazz>()); // Goodstd::unique_ptr<Clazz> up2(new Clazz); // 需要写两次 Clazz 类型
使用 make_unique / make_shared 的劣势
不支持自定义析构器
make 系列函数对形参进行完美转发的代码使用的是小括号初始化,因此在使用 initializer_list 初始化的场景可能不行
make_shared创建的单块内存把指向的内存对象和控制块绑定起来了,因此如果还有weak_ptr指向该对象,由于控制块还需要存在,因此指向的对象内存此时也没法释放了
Lambda 表达式
// https://godbolt.org/z/KE1a9M9Yx
auto a = [](){};
auto b = [](){};
// a 和 b 是同个类型吗?
function<void()> x = a;
function<void()> y = b;
// x 和 y 是同个类型吗?
Lambda 表达式是 C++11 引入的用于构造闭包对象(即能够捕获上下文中变量的匿名函数对象)的方法,常用于 std::find_if 等需要传入特定比较器的场景。
实现原理
Lambda 表达式的基本实现原理是可调用匿名类(所以前面问题的答案就不言自明了),以下写了一个简单的支持 auto 形参(C++14 开始支持)的 Lambda 实现。
// https://godbolt.org/z/EMKMPcTTf
class Lambda_0x8023 {
public:
Lambda_0x8023(int a, string &b): capture_a_(a), capture_b_(b){}
// Lambda 表达式的调用操作符是 const 函数,不能修改值捕获的对象
// C++14 后 constexpr 成员函数本身是 const 成员函数,不需要加 const
template<typename T>
constexpr auto operator()(T param) const {
// capture_a_ = 0x1; // Compile error
capture_b_ = "Modified test lambda: "; // OK
cout << capture_b_ << param << endl;
}
private:
int capture_a_; // 值捕获
string &capture_b_; // 引用捕获
};
int main() {
int a = 0x0;
string b = "Test lambda: ";
// Lambda 的 auto 参数通过匿名类的模版方法来实现
auto lambda_1 = [a, &b](auto x) { cout << b << x << endl; };
lambda_1(0x114);
lambda_1("C++ Lambda test");
// 假装 Lambda_0x8023 是以上 Lambda 表达式生成的匿名类
auto lambda_2 = Lambda_0x8023(a, b);
lambda_2(0x514);
lambda_2("Lambda simple implementation test");
}
变量捕获
按引用捕获需要注意悬垂引用(Dangling references),一旦 Lambda 创建的闭包越过了按引用捕获的变量的声明周期,就会导致引用空悬
// https://godbolt.org/z/3ej7f33Kbvoid add_filter(vector<function<bool(int)>> &filters) {int benchmark = 0x114;filters.emplace_back([&](int val) {cout << "benchmark: " << benchmark << endl;return val == benchmark;});// 离开当前函数后,栈变量将被弹出,此时 &benchmark 处的值未定义}int main() {vector<function<bool(int)>> filters;add_filter(filters);auto f = filters[0];cout << f(0x114) << endl; // false}捕获只能针对在创建 Lambda 表达式的作用域内可见的非静态局部变量(包括形参)
C++14 开始支持广义 Lambda 捕获(支持初始化捕获),就可以开始使用移动构造捕获之类的狠活了(比如把
unique_ptr捕获进来)auto func = [pw = std::move(pw)] { return pw->validated(); };,
Lambda vs. std::bind
优先选择 Lambda 表达式,而不是 std::bind:
Lambda 表达式可读性更好
入参 eval 的时机更明确
支持函数重载
对函数内联更友好(
std::bind通过函数指针调用,编译器趋向于不内联通过函数指针发起的函数调用)std::bind函数参数传递类型不明显对于”捕获“的变量,
std::bind默认是按值存储的,如果需要按引用存储,则需要使用std::ref()函数std::bind返回的结果对象,形参(placeholders)是通过引用传递的
using namespace std::chrono;
using namespace std::literals;
using Time = steady_clock::time_point;
using Duration = steady_clock::duration;
enum class Sound { Beep, Siren, Whistle };
void set_alarm(Time t, Sound s, Duration d);
// 假设我们需要构造一个函数,实现在一小时之后发出警报,并持续 30s
// 使用 Lambda 实现,能够突出我们调用 set_alarm 实现此功能
auto set_sound_lambda = [](Sound s) {
set_alarm(steady_clock::now() + 1h, s, 30s);
}
// 使用 std::bind 实现
auto set_sound_bind_wrong = std::bind(
set_alarm,
steady_clock::now() + 1h, // 这里实际上语义错了,因为实参会在 bind 的时候 eval
placeholders::_1, // 而不是在调用时 eval
30s
);
auto set_sound_bind_correct = std::bind(
set_alarm,
std::bind(std::plus<steady_clock::time_point>(), steady_clock::now(), 1h),
placeholders::_1,
30s
);
void set_alarm(Time t, Sound s, Duration d, Volume v);
// 发生函数重载,此时 std::bind 的调用无法编译(bind 拿到的信息只有函数名称)
abseil 提供了 bind_front 函数,相比 std::bind 在多数情况下更易用。
实践杂谈
初始化方法的选择
C++ 11 引入了统一初始化( {} 初始化),至此,各种初始化方法整体比较如下图所示:

(图源 http://josuttis.com/cpp/c++initialization.pdf )
统一初始化的优势主要有:
相比其他初始化方式适用范围更广
复制初始化不能用于
atomic等不可复制的对象()初始化有时候会不可用,例如Clazz c();声明的是函数Clazz ()而不是Clazz变量禁止 built-in 类型之间进行 narrowing conversion,还是能避免一些隐藏的类型转换问题的
不过,当统一初始化遇到 std::initializer_list 时,编译器会尽可能匹配形参为 std::initializer_list 的函数重载版本,例如:
std::vector<int> v1(10, 20); // 创建一个包含 10 个元素的 vector,每个元素都是 20
std::vector<int> v2{10, 20}; // 创建一个包含 2 个元素的 vector,分别为 10 和 20
这里比较推荐 abseil 关于初始化的实践:
对于初始化过程仅涉及简单的类型定义或复制的场景(例如字面量初始化、复制初始化等),使用
=初始化int x = 2;std::string foo = "Hello World";std::vector<int> v = {1, 2, 3};std::unique_ptr<Matrix> matrix = NewMatrix(rows, cols);MyStruct x = {true, 5.0};MyProto copied_proto = original_proto;对于初始化过程涉及构造逻辑的场景,使用
()初始化Frobber frobber(size, &bazzer_to_duplicate);std::vector<double> fifty_pies(50, 3.14);当以上两种方法无法编译时,才使用
{}初始化
优先使用 nullptr ,而不是 0 或 NULL
nullptr 是 C++11 引入的纯右值,其类型为 nullptr_t ,可以隐式转换为任何指针类型。
因此,相比 0 和 NULL , nullptr_t 可以避免调用到接受其他类型形参的函数重载版本。
void f(int);
void f(bool);
void f(void*);
f(0); // 调用 f(int)
f(NULL); // 在大部分编译器下编译失败
f(nullptr); // 调用 f(void*)
优先使用 using ,而不是 typedef
using可读性更好
typedef void (*FP)(int, const std::string&);
using FP = void (*)(int, const std::string&);
using支持模板化,但typedef不支持
template<class T>
struct Alloc {};
template<class T>
using Vec = vector<T, Alloc<T>>; // type-id is vector<T, Alloc<T>>
Vec<int> v; // Vec<int> is the same as vector<int, Alloc<int>>
using模板可以避免::type后缀,同时也不需要考虑模板内带依赖类型的typename前缀;C++14 正是在 type traits 中引入了using,使其语法友好了很多
std::remove_const<T>::type // C++11
std::remove_const_t<T> // C++14
优先使用 enum class ,而不是 enum
enum class可以避免enum带来的命名空间污染
enum Color { red, green, blue };
auto red = false; // Compile error,enum Color 污染了当前的命名空间
enum class Color { red, green, blue };
Color c1 = red; // Compile error
Color c2 = Color::red; // OK
auto c3 = Color::red; // OK
enum class不能隐式转换为其他类型
enum Color { red, green, blue };
Color c = red;
if (c < 11.4); // OK
enum class Color { red, green, blue };
Color c = Color::red;
if (c < 11.4) {} // Compile error
enum class的默认底层类型是int,而enum没有默认底层类型(节省空间) 这意味enum仅在指定底层类型的情况下才可以进行前置声明;同时默认情况下,若enum的定义发生扩充(例如新增了一个枚举),enum的底层类型就可能会改变,依赖到enum的编译单元都需要重新编译了
为需要改写的函数都显式添加 override 声明
发生函数重载是需要一些条件的:
函数名称相同
形参类型相同
常量性相同
返回值和异常类型可兼容
函数引用限定符(C++11,用于限制函数仅用于左值或右值)相同
在编写重写的函数时,可能会因为某些条件没有满足导致没有真正重写(有可能发生 function shadowing),这时候加上 override 就能让编译器产生错误信息了。
优先使用 const_iterator ,而不是 iterator
const_iterator 和 iterator 本质上都是 normal_iterator 的 alias,区别在于 _Iterator 类型的不同( pointer 和 const_pointer )
// libstdc++: stl_vector.h
// https://gcc.gnu.org/onlinedocs/gcc-4.8.2/libstdc++/api/a01570_source.html
227: typedef __gnu_cxx::__normal_iterator<pointer, vector> iterator;
228: typedef __gnu_cxx::__normal_iterator<const_pointer, vector> const_iterator;
// libstdc++: stl_iterator.h
// https://gcc.gnu.org/onlinedocs/gcc-6.3.0/libstdc++/api/a01623_source.html
756: template<typename _Iterator, typename _Container>
757: class __normal_iterator
758: {
759: protected:
760: _Iterator _M_current;
761:
762: typedef iterator_traits<_Iterator> __traits_type;
const_iterator 不能用于修改容器元素,因此,在不需要通过迭代器修改变量的情况下,尽量使用 const 版本的迭代器相关的成员函数(例如 cbegin() 、 cend() )。
不过,在容器本身就使用 const 修饰的情况下,调用其普通版本的迭代器相关函数(例如 begin() )也会返回 const_iterator ,具体情况如下所示:
// https://godbolt.org/z/jj5e77T3Y
vector<int> v;
const vector<int> cv = v;
v.begin(); // type: __gnu_cxx::__normal_iterator<int*, std::vector<int, std::allocator<int> > >
v.cbegin(); // type: __gnu_cxx::__normal_iterator<int const*, std::vector<int, std::allocator<int> > >
cv.begin(); // type: __gnu_cxx::__normal_iterator<int const*, std::vector<int, std::allocator<int> > >
cv.cbegin(); // type: __gnu_cxx::__normal_iterator<int const*, std::vector<int, std::allocator<int> > >
int target = 0; // Readonly find
const auto it1 = find(v.begin(), v.end(), target); // Bad
const auto it2 = find(v.cbegin(), v.cend(), target); // Good
const auto it3 = find(cv.begin(), cv.end(), target); // Acceptable
const auto it4 = find(cv.cbegin(), cv.cend(), target); // Good
因此,
对于非
const容器变量,在不通过迭代器修改变量的情况下,使用const版本的迭代器相关成员函数对于
const容器变量,则都可以接受,但还是尽量使用const的版本(因为容器的 constness 可能会在后续的代码改动中发生变化)
确定函数不会异常后,可以加上 noexcept 声明
加上
noexcept声明有利于函数编译器更好地优化代码编写类的移动构造函数时,加上
noexcept声明可以在其作为vector等容器的元素时,在容器发生 resize 的情况下,将元素的复制操作替换成低成本的移动操作大部分函数是异常中立的,函数本身不抛出异常,但其调用的函数不保证不产生异常(在我们的业务代码中,涉及 RPC 调用的代码基本都属于这种情况,可能只有少部分工具类代码可保证不产生异常)
优先使用 constexpr ,而不是 const
constexpr 是 C++11 引入的编译期常量表达式的修饰符,相比而言 const 则仅保证某个变量在运行时保持不变。具备编译期可知的特性之后,用 constexpr 修饰的变量就可以用于标识数组大小、switch case label 等场景了。
// https://godbolt.org/z/fWEn4Kcfb
// constexpr 用于函数时,表明函数本身的“推断行为”编译期可知:
// - 当函数接受 constexpr 入参时,返回 constexpr 常量
// - 当函数接受非 constexpr 入参时,也返回非 constexpr 变量
constexpr int get_compile_time_value(int x) {
return x;
}
int get_runtime_value() {
return 0;
}
int main() {
// constexpr 用于变量时,仅能修饰编译期常量
constexpr int x = get_runtime_value(); // Compile error
constexpr int a = 0x114;
constexpr int y = get_compile_time_value(a); // OK
int b = 0x514;
constexpr int z = get_compile_time_value(b); // Compile error
}
C++11 中, constexpr 函数最多只能包含一条可执行语句,即 return 语句;C++14 以后不再有这个限制。
C++11 中, constexpr 成员函数会被隐式地加上 const 修饰符,此时 constexpr 成员函数不能用于修改类的成员变量(当然可以通过 mutable 规避);C++14 以后不再有这个限制。
C++11 类成员函数的生成机制
// https://godbolt.org/z/xqKK6a5e4
class Clazz {
public:
// 默认构造函数
// 仅当类中没有显式声明任何构造函数时才生成
Clazz();
// 析构函数
// 1. 析构函数默认为 noexcept
// 2. 仅当基类的析构函数为虚时,派生类默认生成的析构函数才是虚的
~Clazz();
// 复制构造函数/赋值运算符
// 1. 默认生成的复制构造函数将会依次调用非静态类成员变量的复制构造函数
// 2. 复制构造函数和赋值运算符**相互独立**,声明了其中一个并不会阻止编译器生成另一个
// 3. 显式声明移动操作会导致编译器**删除**复制操作
// 显式声明移动操作的类,可能是不可复制的,例如 unique_ptr
Clazz(const Clazz &rhs);
Clazz& operator=(const Clazz &rhs);
// 移动构造函数/赋值运算符
// 1. 默认生成的移动构造函数将会依次调用非静态类成员变量的移动构造函数
// 若成员不可移动,则调用其复制构造函数
// 2. 移动构造函数和赋值运算符**不相互独立**
// 当显式声明移动操作时,说明你很可能在默认实现的基础上还需要进行其他的操作,
// 因此编译器生成的版本很有可能是不适用的
// 3. 显式声明复制操作或析构函数会阻止编译器生成移动操作
// 声明复制操作表明编译器的默认实现(按成员复制)不适用,而移动操作的默认实现很可能
// 包含成员的复制操作,因此大概率也是不适用的
Clazz(Clazz &&rhs);
Clazz& operator=(Clazz&& rhs);
};
类成员函数生成规则总结:
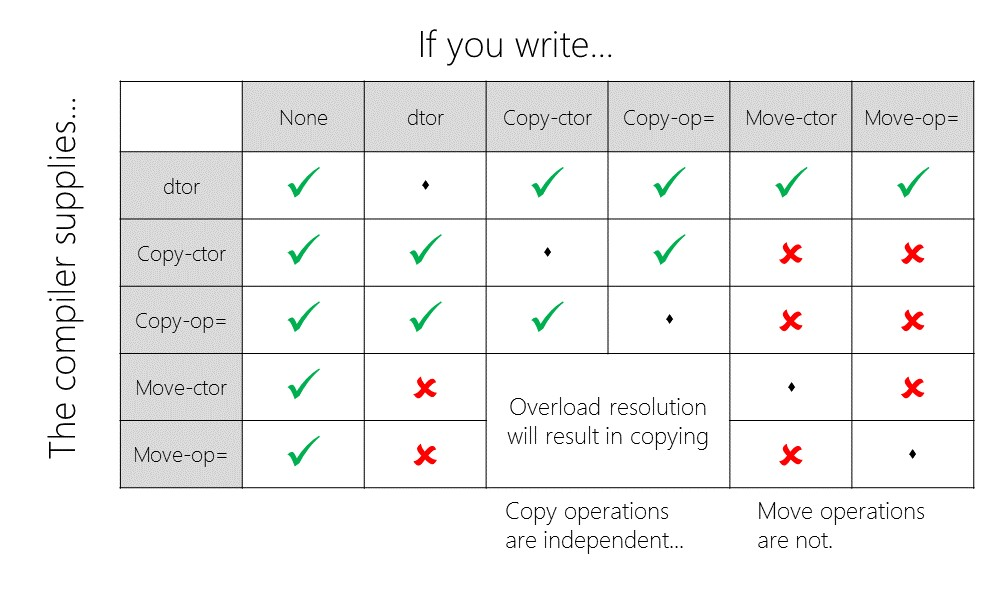
类成员函数生成特征:
当生成派生类的析构函数时,若基类的析构函数是个虚函数,则派生类生成的析构函数也是虚函数
其他情况下,编译器生成的成员函数都是
public且inline的
另外,成员函数模板在任何情况下都不会抑制成员函数的生成。
使用 auto
在 clangd + clang-format + clang-tidy 的加持下,建议多使用 auto 而不是显式地声明变量类型
大部分情况下,你都很确定这个类型是啥,例如
const auto it = std::find(...);,没有必要显式把变量类型标识出来;clangd 会显示it的推导类型,Code reviewer 在这种情况下相信也不会因为auto而困惑少部分情况下,你其实并不真的知道函数返回的类型,这时候
auto能降低你的一些心理负担,避免一些代码问题(不过这里就有利有弊了)
// https://godbolt.org/z/ocdvT6G7P
// Case 1
unordered_map<int, string> m = {{0x1, "Hello"}};
for (const auto &kv : m) { // Good
// kv.first 为 int const 类型,而非 int 类型
}
// 存在隐式转换,造成多余的性能损失
for (const pair<int, string> &kv : m) {...} // Bad
// C++17 结构化绑定
for (const auto &[k, v] : m) {...} // Good, I love it
// Case 2
vector<bool> v = {false, true};
const auto first = v.at(0); // Bad, or use static_cast later
// first 为 std::_Bit_reference 类型,而非 bool 类型
// ref: https://en.cppreference.com/w/cpp/container/vector_bool
const bool first = v.at(0); // Implicitly transformed
使用 std::function 代替函数指针
std::function 是 C++11 标准库中的一个模板,将函数指针的思想推广为任何的可调用对象(即重载了 () 操作符的对象)。相比函数指针,其适用性更广,代码可读性也更好,还可以跟 std::bind 、 absl::bind_front 、 Lambda 表达式等特性结合。
使用 chrono 时间工具库
chrono 时间工具库相比 std::time 不管是从表达力还是从易用性上都好很多,chrono_literals 的加入更是让代码可读性更上一个台阶。日常业务开发中我们时常会有计算某段子例程执行时间的需求,这时候用 chrono 就很合适。
#include <chrono>
auto start = std::chrono::steady_clock::now();
// Doing stuffs changing the world
auto end = std::chrono::steady_clock::now();
std::chrono::duration<double> elapsed_seconds = end - start;
// Report
尝试使用 Trailing return type
Trailing return type 是 C++11 引入的函数返回值声明语法,相比常规的函数声明语法更能突显函数的返回类型。
char const *func1(void f(bool&));auto func2(void f(bool&)) -> char const*;如果返回值类型是通过
decltype声明,且decltype依赖入参,则此时必须使用 Trailing return typedecltype(a.end()) end_1(const vector<int> &a) { // Compile errorreturn a.end();}auto end_2(const vector<int> &a) -> decltype(a.end()) { // OKreturn a.end();}decltype(auto) end_3(const vector<int> &a) { // OK since C++14return a.end();}
开始使用 Attribute
Attribute specifier sequence 是 C++11 开始引入的用于增强语义或进行编译器 hint 的特性,以下列举几个可以开始尝试的 attributes,具体可以自己多加探索(实际上就是我才疏学浅,用的不多)。
[[nodiscard]](since C++17) 目前觉得最好用的 attribute,可以用于修饰函数,表示该函数的返回值不可忽略,对于业务代码中常用ret作为返回值的场景还是比较有帮助的;特别是对于带返回值的纯函数(例如 const 成员函数),如果忽略了返回值,那实际上调用这个函数基本是无意义的(先不考虑修改 mutable 成员变量的情况)[[gnu::always_inline]](GCC) 配合inline使用,强制内联[[deprecated]](since C++14)
多用 <algorithm> 代替手撸小轮子
<algorithm> 库里有很多宝藏( std::find_if 、 std::lower_bound 、 std::includes …),细心的人才看得到。
C++11 并发库
C++11 开始引入 std::thread ,相比 pthread 抽象层级更高,更易用,同时还有其他诸如 std::atomic 、 std::async 等并发 API,助力有锁 / 无锁的并发编程。不过并发这个话题还是有点太大了,本菜鸡也只是写过一点 demo,就推荐一些认为读过(或没读过)感觉还不错的文章和书籍了。
下一步
C++17 → C++20/23 → Stackless coroutines → Template metaprogramming → Compiler …
最后「精通 C++」 ❎ 拥抱 Rust ✅
感谢你看到(或划到)这里 🥳,希望大家多多交流,多多指正,分享你的学习路线、资源和方法,像我这样的 C++ 菜鸡能救一个是一个 🤣
