书接上回,此番我们来探讨一下 CMU 15-445 P2 的优化策略。
温馨提示:
- 本文适用于 P2 实验部分已经完成、希望探讨 P2 优化思路和方案的同学,关于实验的正确实现请独立思考和实现
- 本文中 P2 的优化方案并不基于上文中 P1 的优化,可以独立阅读,欢迎大佬们一起讨论潜在的优化空间 ;-)
优化结果
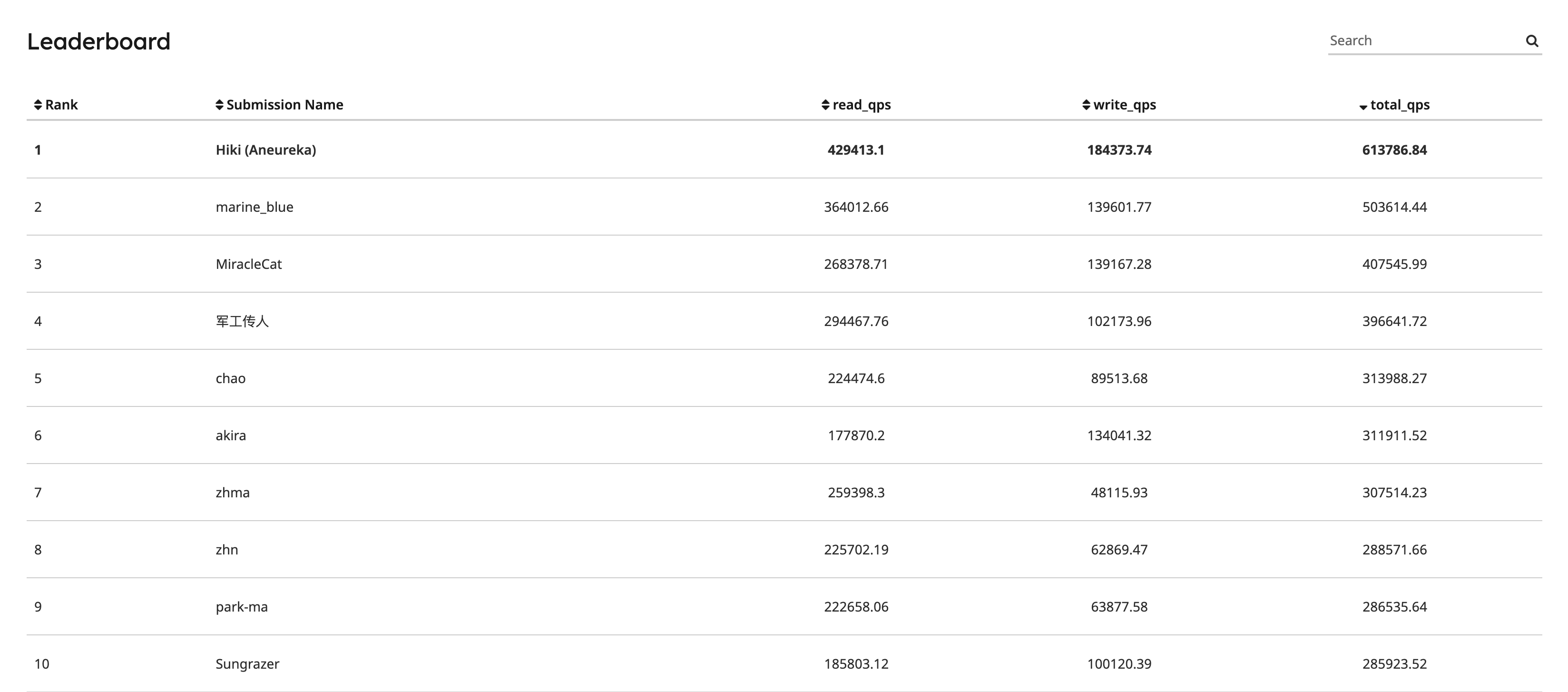
经过优化后,在 Leaderboard 中暂列第一(2023-07-21)☃️
Workload 分析
照例,我们先看下 P2 的 benchmark 做了什么事情:
- 初始化 B+ 树:调用 BPlusTree::Insert 按顺序插入总共 100000 个键值对(此过程不计入性能指标)
- 使用 4 个读线程和 2 个写线程并发、随机、稀疏地读写 B+ 树(统计性能指标)
因此,我们重点需要优化的是步骤 2 的性能表现。在步骤 2 开始前,B+ 树已经被初始化构建完成,所以我们应该尽量减少步骤 2 稀疏写操作对 B+ 树的结构产生影响,最好是保持所有的写操作都能原地完成而无需进行节点的调整(例如节点的分裂和合并)。
到这里,在没有其他信息辅助的情况下,我们可以初步得出优化路线:
利用 B+ 树初始化过程的有序性,保证 B+ 树初始化后到达一个相对稳定的状态(即不会因为后续的稀疏写操作发生节点分裂、合并等调整),然后通过乐观锁加速后续的读写操作。
确定整体的优化路线之后,如上文所说,profiling 也是一个非常重要的优化目标来源,因此接下来我们会不断经历「做 profiling -> 寻找性能瓶颈 -> 思考优化方案 -> 实现优化方案 -> 重新 profiling」的过程,本文也会沿着这个思路,按照子优化项组织和展开。
优化一:LRU-K -> LRU
按照国际惯例,先跑个火焰图吧。
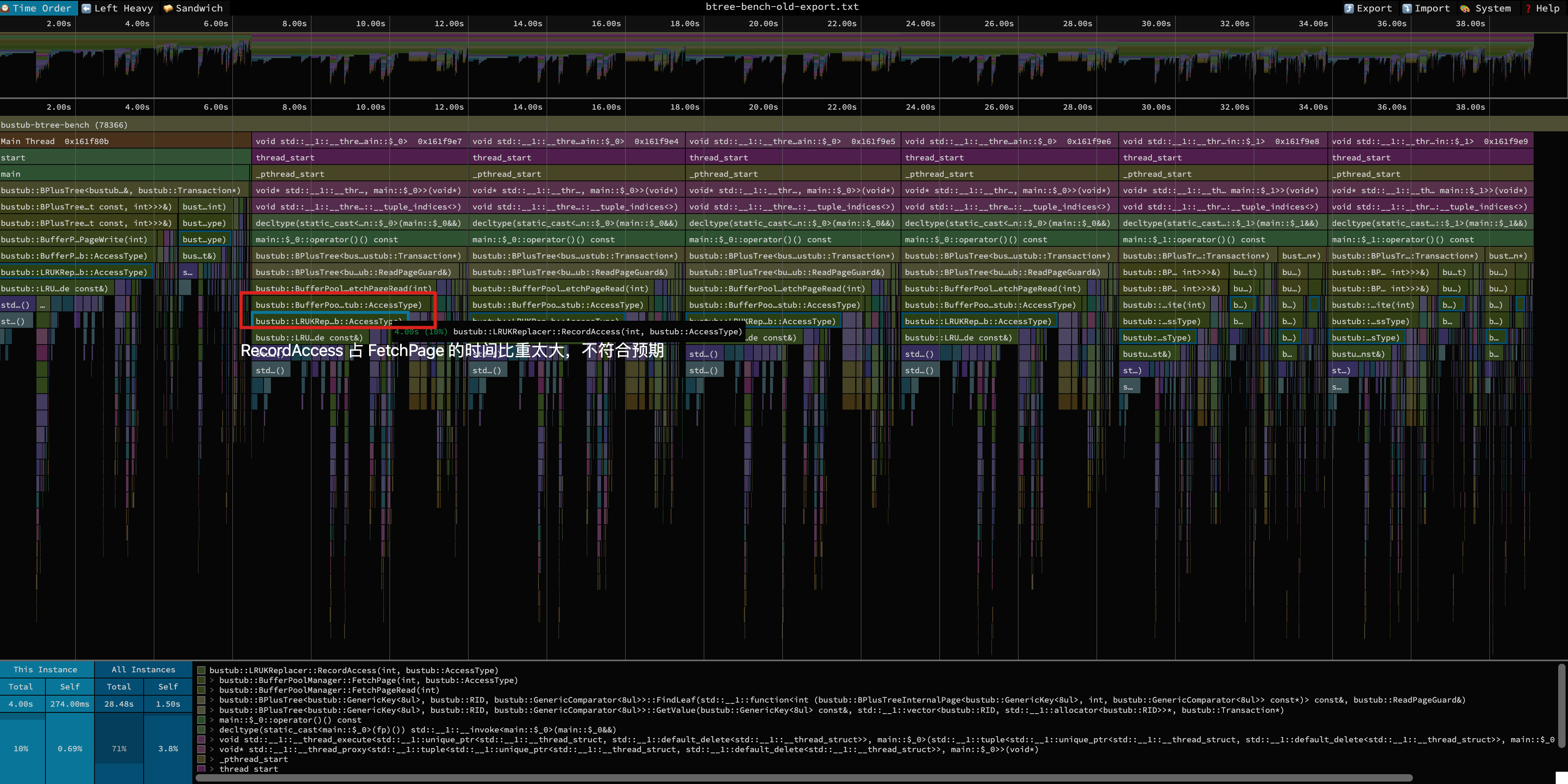
这个图看上去貌似没什么毛病,但仔细观察就能窥见端倪:LRUKReplacer::RecordAccess 占了 FetchPage 接近 90% 的时间!这意味着 FetchPage 以博尔特的速度跑完空闲队列读写、新页初始化、页帧映射关系读写等一系列的操作后,在 LRUKReplacer 这里点了杯咖啡,喝完再跑到终点。这明显是不符合预期的。
于是我们深入代码,发现在 LRUKReplacer 目前的实现中,当某个节点访问满 K 次时,后续记录访问时间需要不断更新它在「已满 K 次访问的节点链表」中的位置,这个操作是 O(N) 的,占了 RecordAccess 执行时间的 80%(为什么 P1 没有出现这个问题?因为在 P1 中绝大多数节点活不到访问满 K 次(x
因此我们考虑把这个 O(N) 的耗时操作优化到 O(1),怎么优化?“降级”到 LRU 呀。LRU 相比 LRU-K 最大的优势是 RecordAccess 可以以 O(1) 的时间完成,而且其淘汰策略见不得比 LRU-K 差,同时 P2 也不会对 LRUKReplacer 实现做约束,那不就可以偷家了嘛。
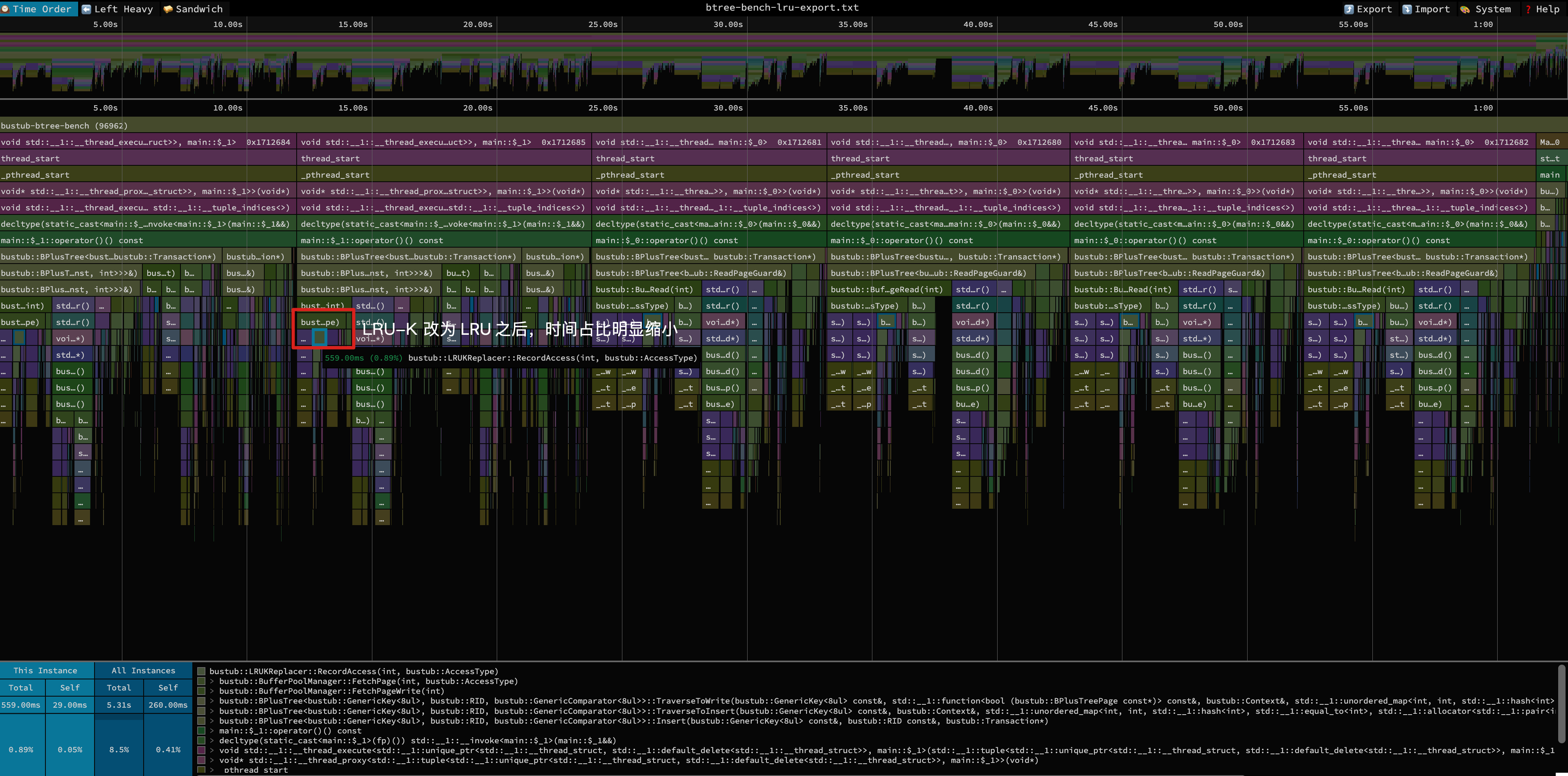
花 20 分钟左右进行 LRU-K -> LRU 改造后,我们就轻松获得了超过两倍的 QPS 提升。可以看到,在切到 LRU 后,FetchPage 时间缩短了,RecordAccess 的时间占比也明显缩小了(优化后时间占比仅为 20%)。
优化二:B+ 树节点插入后重分布 + 乐观锁
这理应是我们的重头戏 ;-)
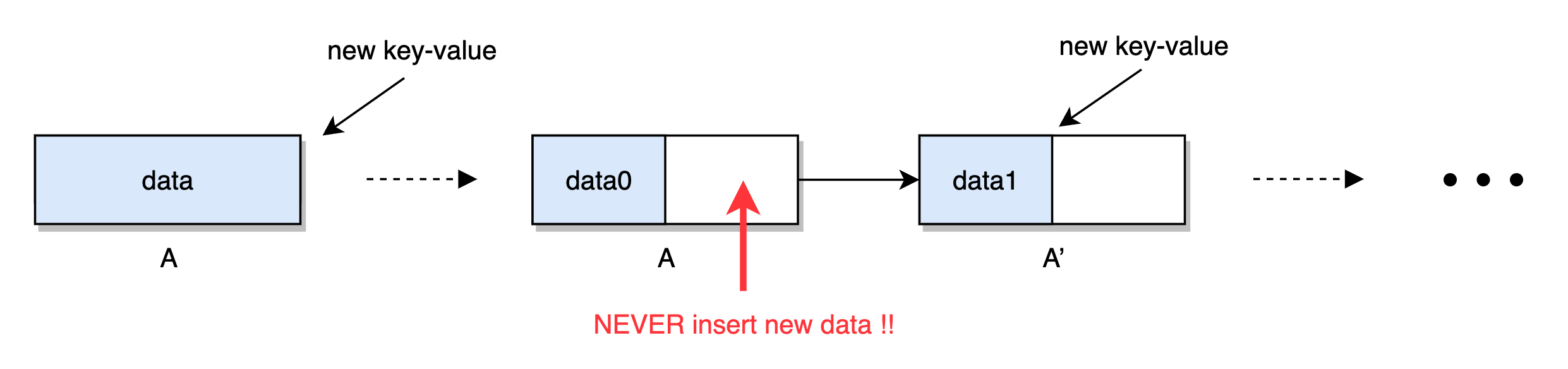
什么节点是不稳定的?即将发生分裂或合并的节点,也即接近半满和饱和的节点。在我们目前的实现中,B+ 树被顺序插入数据后实际上叶子节点几乎都处于一个不稳定的状态。例如一个叶子节点 A 在插入数据指到饱和并分裂后,形成新的半满节点 A 和 A',由于是顺序插入,所以新的数据会被填充到 A',而 A 就不会再被插入数据了,接着 A' 也享受与 A 一样的待遇,如此反复,直到 B+ 树的叶子节点中除了最后一个节点外都是 50% 填充率。
通过对 benchmark 过程中,B+ 树发生的分裂和合并次数的统计(步骤一发生的分裂和合并不计入),我们也能发现在优化前 B+ 树调整的次数还是挺高的。
优化前(初始化过程不计入):
#insert: 590645
#split: 774
#remove: 173677
#merge or redistribute: 18151因此,在遇到插入饱和节点的时候,我们要优先赠与部分数据给左边兄弟节点,其次再考虑分裂当前节点。给多少节点好呢?理论上在均匀插入、删除的时候,应该是半满和饱和的中间值最好(即 75% 左右)。不过观察上面的数据,合并发生的概率比分裂高很多,所以我们应该适当把填充率调高。加上好久之前就看到群青大佬的文章,所以我第一次就尝试了 90% 的填充率,发现优化后在步骤二完全不发生分裂和合并,所以就直接运用了前人的智慧~
优化后(初始化过程不计入):
#insert: 591156
#split: 0
#remove: 173454
#merge or redistribute: 0做好 B+ 树插入的优化后,我们就可以开始用乐观锁代替悲观锁,只在叶子节点发生写锁同步,从而保证在 crabbing 过程的并发度维持在一个较高的水平。
经此一役,QPS 应该有显著提升吧?自信满满地提交了一波 Leaderboard,发现 QPS 只有原来的 1.25 倍!!
怎么回事?
优化三:Buffer Pool 分段
再跑一次 profiling ——
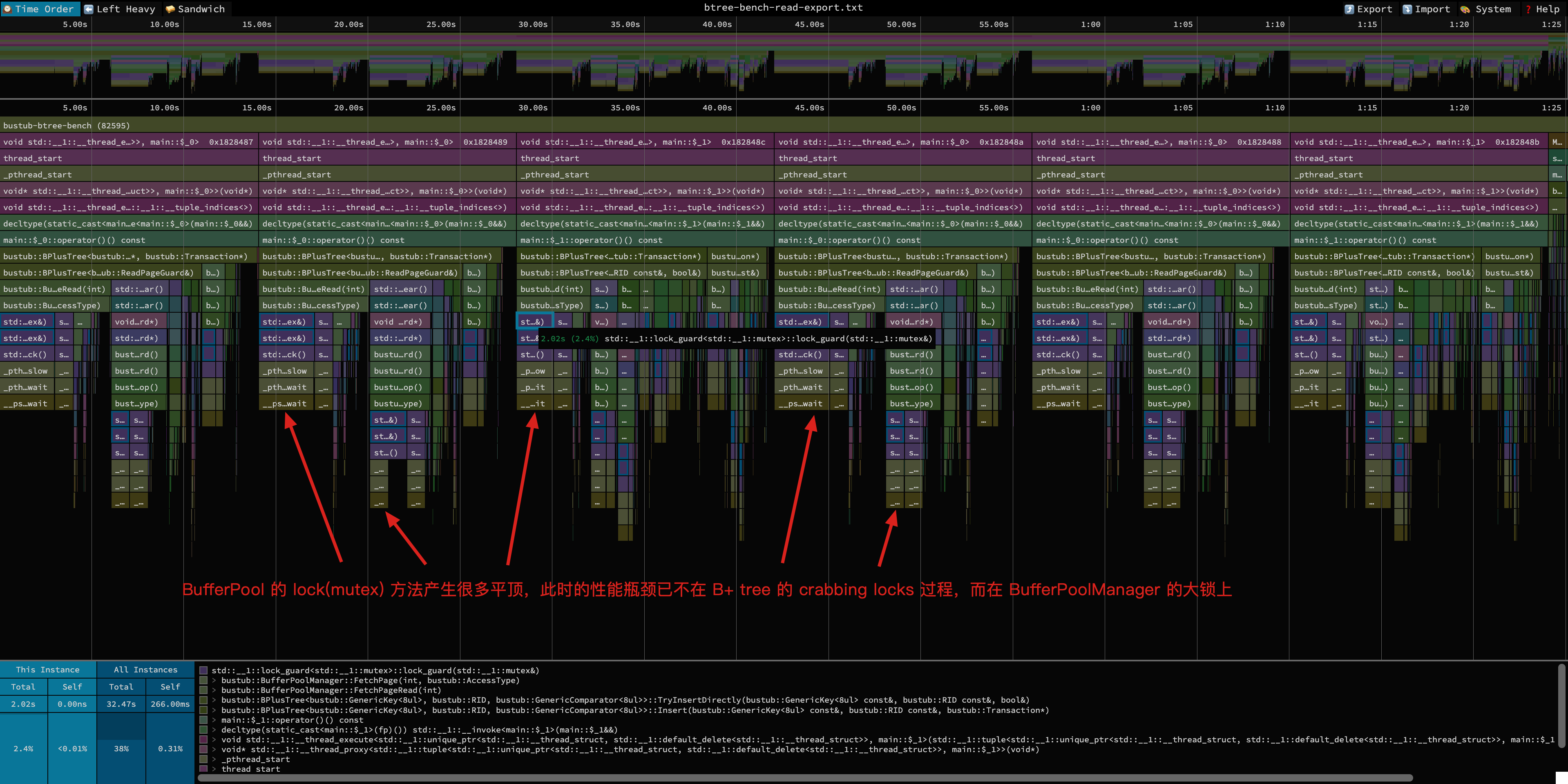
发现火焰图中产生很多平顶,全在 BufferPoolManager 的大锁上,至此我们知道 B+ 树本身的性能已经被差不多榨干了,BufferPoolManager 的大锁作为隐藏 boss 跳出来了。
在 P2 的 benchmark 中,由于 DiskManager 采用的是 0ms 延迟的 DiskManagerUnlimitedMemory,因此基本不构成性能瓶颈,反而是 BufferPoolManager 的大锁坏了事情。因此,联想到 Java 中 ConcurrentHashMap 的分段锁优化和各种热 key 拆分策略(知识迁移),我们也可以尝试将 BufferPool 分段,将大锁拆分成几把段锁,每把锁协调一部分资源的调度,然后再根据 page_id 做 hash 进行请求分发,岂不美哉?整体思路对应视图如下:
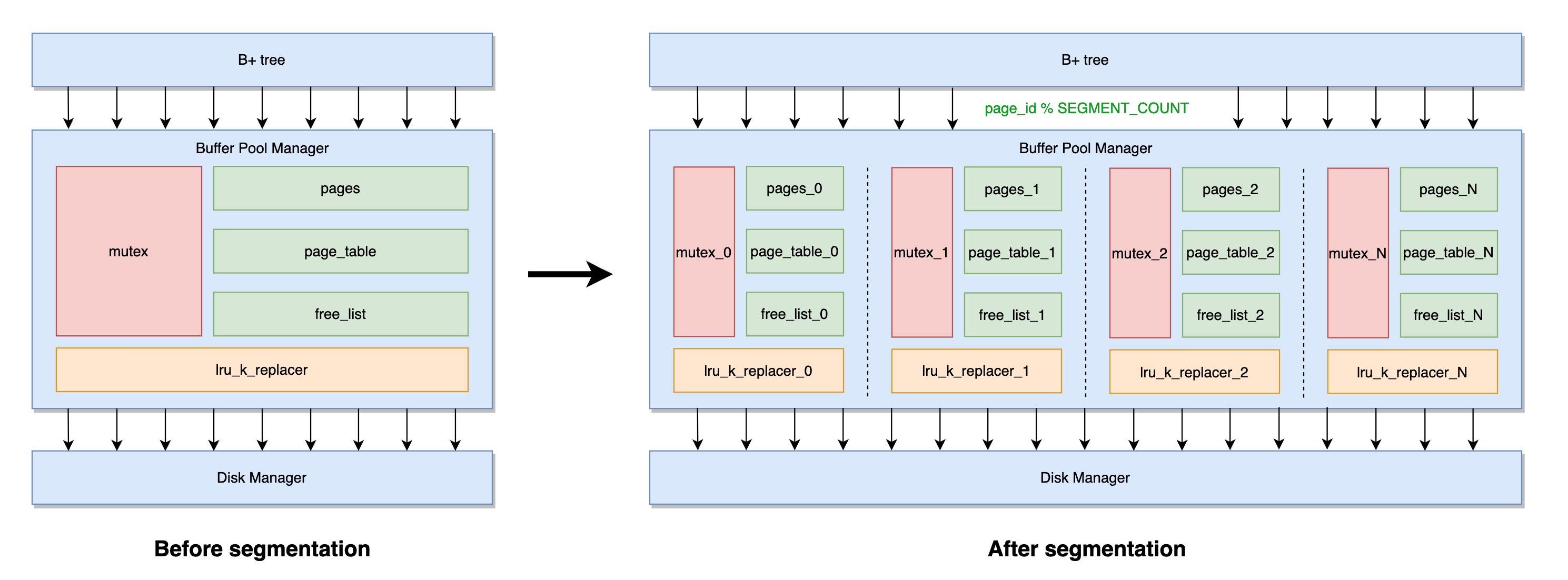
分段也会产生一些问题:
- 什么时候分段?分为几段?由于分段也会产生额外的 overhead,而且在 pool size 较小时,大锁可能并不是瓶颈,所以我们可以划分一个触发分段的 pool size,比如为 256 ;-) 另外,经过测试,分段数为 12 左右时,性能表现较高
- 分段可能导致缓冲池资源分布不均问题:例如在 pool_size=32、segment_count=8 时,考虑一个极端情况,下游有个线程正在不断读写 page_id=0,8,16,24 的页面,把 segment_index=0 的子缓冲池占满,此时如果有另一个线程需要读写 page_id=32,40 的页面就会发现缓冲池 FetchPage 失败;但在分段前是没有这个问题的
- 解决方案:在 pool size 较大的场景才开始分段,分段数不能过高,其次真实场景中一般读写是比较均匀的
- 题外话:在正常的资源拆分处理中,会有跳单策略,但我们这个场景并不适合
做完 BufferPool 分段优化后,QPS 再次提升了两倍 (20w -> 60w),登顶 Leaderboard~ 🎊
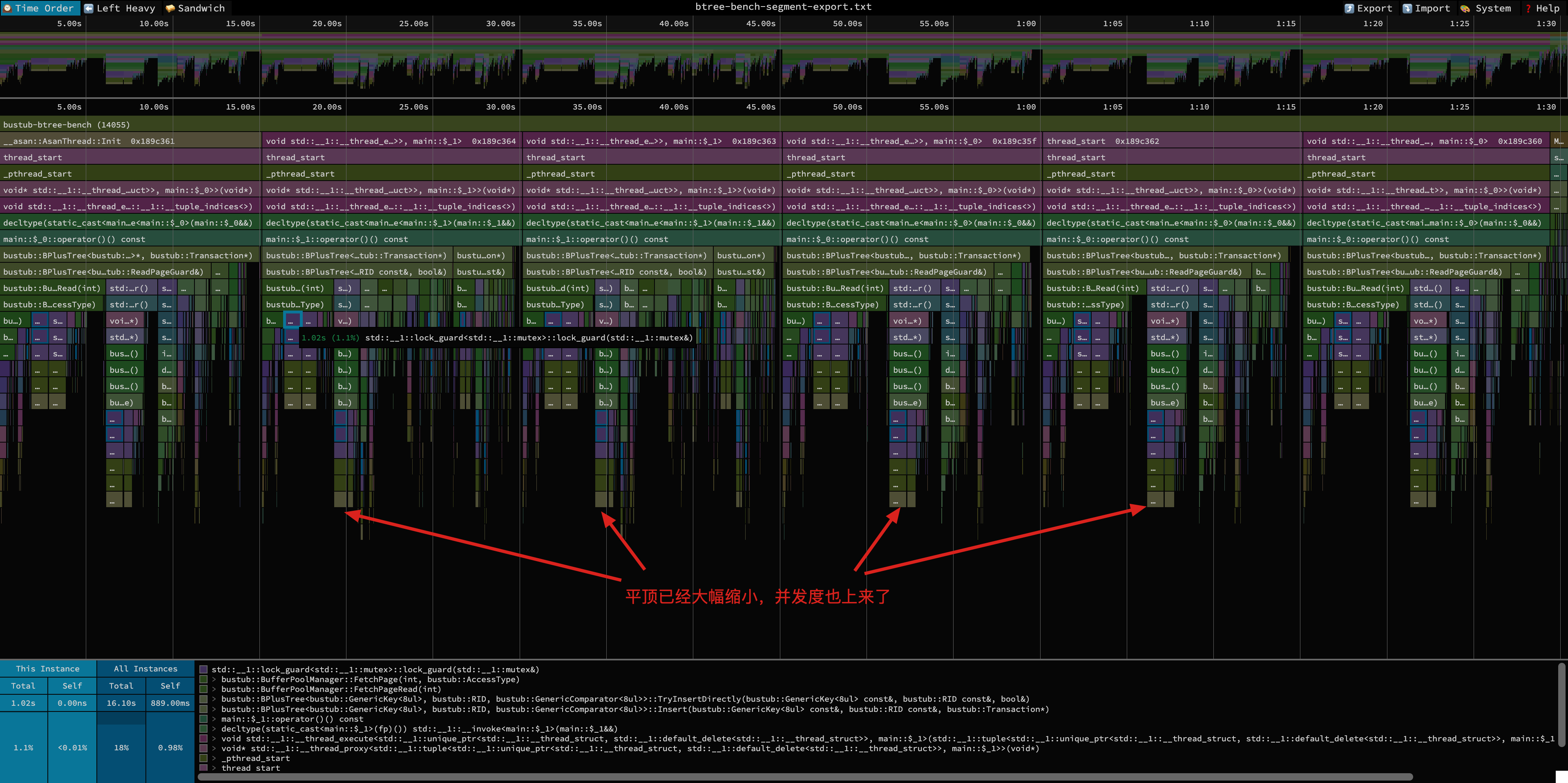
看看做完优化后的火焰图,可以看到平顶已大幅缩小,并发度也提高了。
总结
整个优化和文章记录的过程跟 P1 差不多,耗时两天左右,又是收获满满~
PS: P3 和 P4 的优化暂时应该不动笔了,当下有其他更重要的事情需要完成,后面有空再来写写(当然也有一定概率真香哈哈哈)~ 期待大佬们的思路~
如果一定要有一个 takeaway,我觉得是「性能调优要遵循基本法」 🥵
最后,希望你看完本文有所收获,然后吃顿好吃的 🥳
