最近把 CMU 15-445 (2023) 的实验部分做完了,刚好找一个周日琢磨一下优化的部分,于是就开始了愉快的 P1 优化之旅。
温馨提示:本文适用于 P1 实验部分已经完成(做完 P4 理解会更深刻)、希望探讨 P1 优化思路和方案的同学。本文仅是引蛇出洞,欢迎大佬们一起讨论~
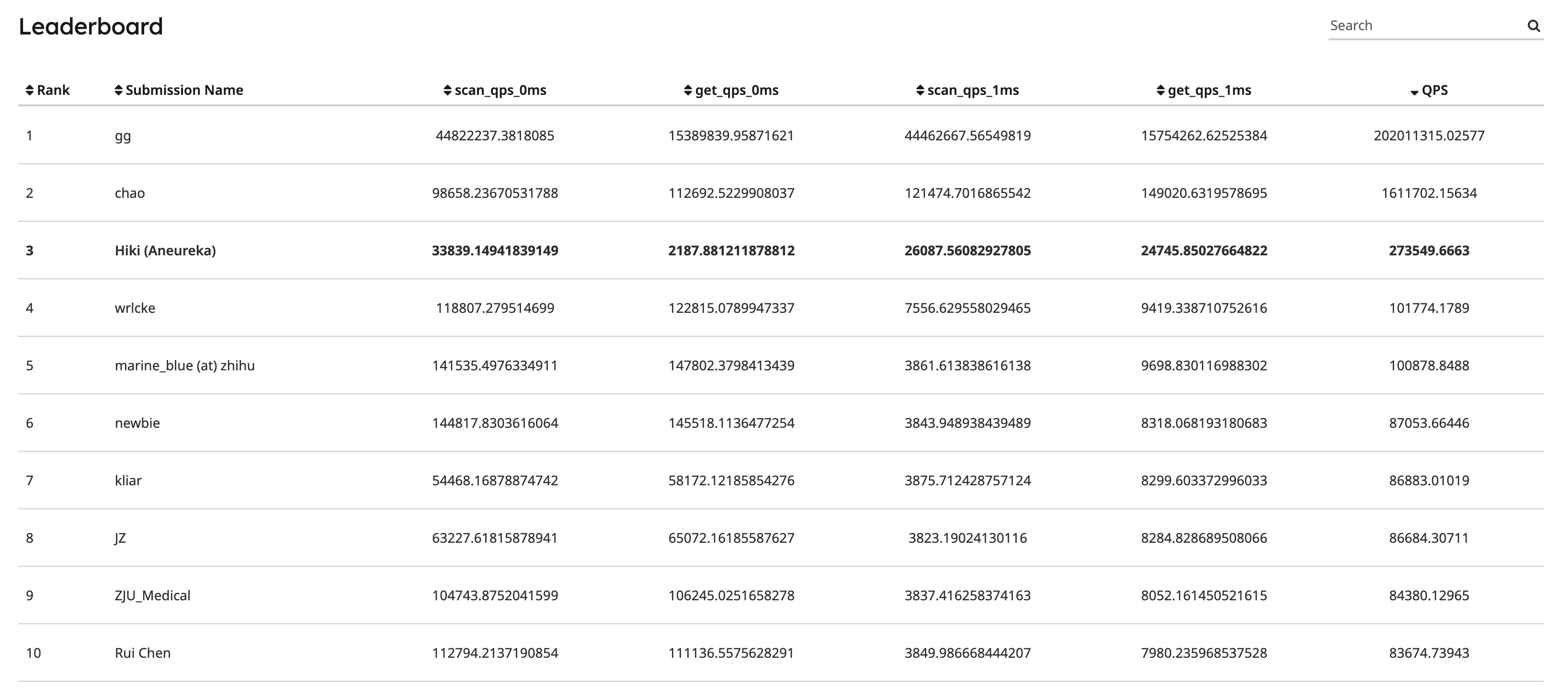
优化结果
经过优化后,在 Leaderboard 中暂列第三(2023-07-17,top1 不知道是什么神仙 orz)
分析 Workload,明确优化方向
第一步,我们要先搞清楚 benchmark 做了什么事情、如何计分,才能制定优化的目标,划分优化项的优先级。
从实验文档和源码都可以看出,bpm-bench 是通过 8 个 scan 线程和 8 个 get 线程并发读取和更新 BufferPool 中的页面,其中 scan 是顺序读写,get 是基于 zipfian distribution 的随机读写。另外,硬盘是使用来模拟读写操作,并通过设定 sleep 时间来模拟硬盘读写的延迟(可见源码)。
最终的分数则是通过加权计算硬盘读写延迟设定为 0ms 和 1ms 时的 BufferPool QPS 来综合计算:
scan_qps_0ms / 10000 + get_qps_0ms / 10000 + scan_qps_1ms + get_qps_1ms * 10可以看到,硬盘 1ms 读写延迟对应的 BufferPool 性能测试结果权重相比 0ms 高非常多,并且 get 是 scan 是 10 倍,即 benchmark 非常注重 BufferPool 在接近真实场景下的性能表现。因此,到这里我们也可以得出优化目标:
- 提高 BufferPool 在硬盘 1ms 延迟下的性能(高优先级)
- 针对 scan 场景做特定优化(低优先级)
Profiling
在明确优化目标之后,我们可以通过 Profiling) 验证 BufferPool 在 benchmark 的 workload 下,是不是如期表现,同时看看有没有其他值得优化的地方。
目前我的实现跟大家差不多,BufferPool 通过一个 mutex(大锁)同步对缓冲池的读写操作,LRUKReplacer 则是通过维护 1.未满 K 次访问 2.满 K 次访问 的 frame 链表实现。因此,对于硬盘读写 0ms 延迟的场景,表现目测会还可以;但对于 1ms 延迟的场景,我们就可以预见到 BufferPool 某一线程拿完大锁然后卡在硬盘读写的场景了,这种情况下 QPS 最高也只能达到 1000 左右。
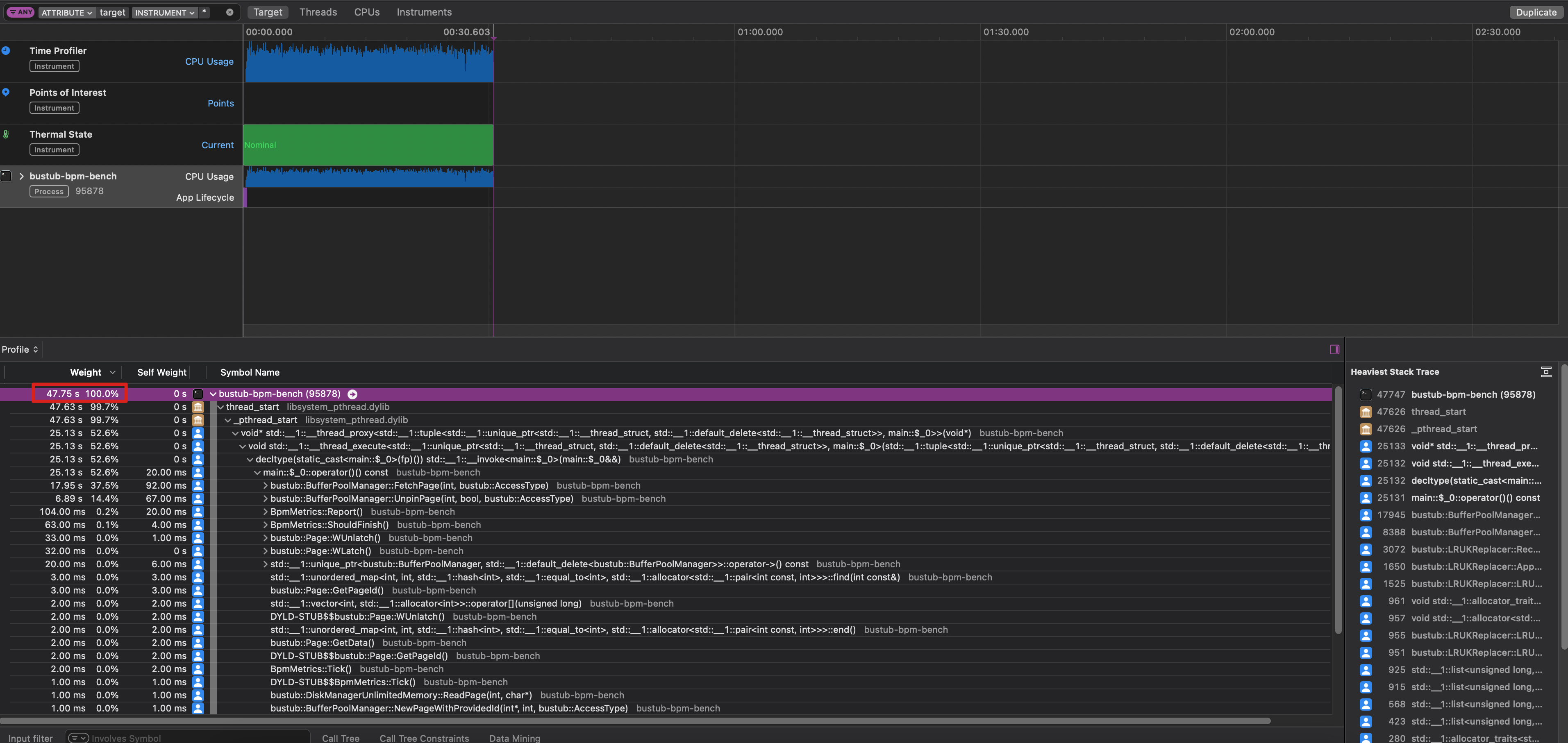
那..开始验证吧,在 MacOS 上用 Instruments 分别就 0ms 和 1ms 的场景做 profiling,得到以下结果:
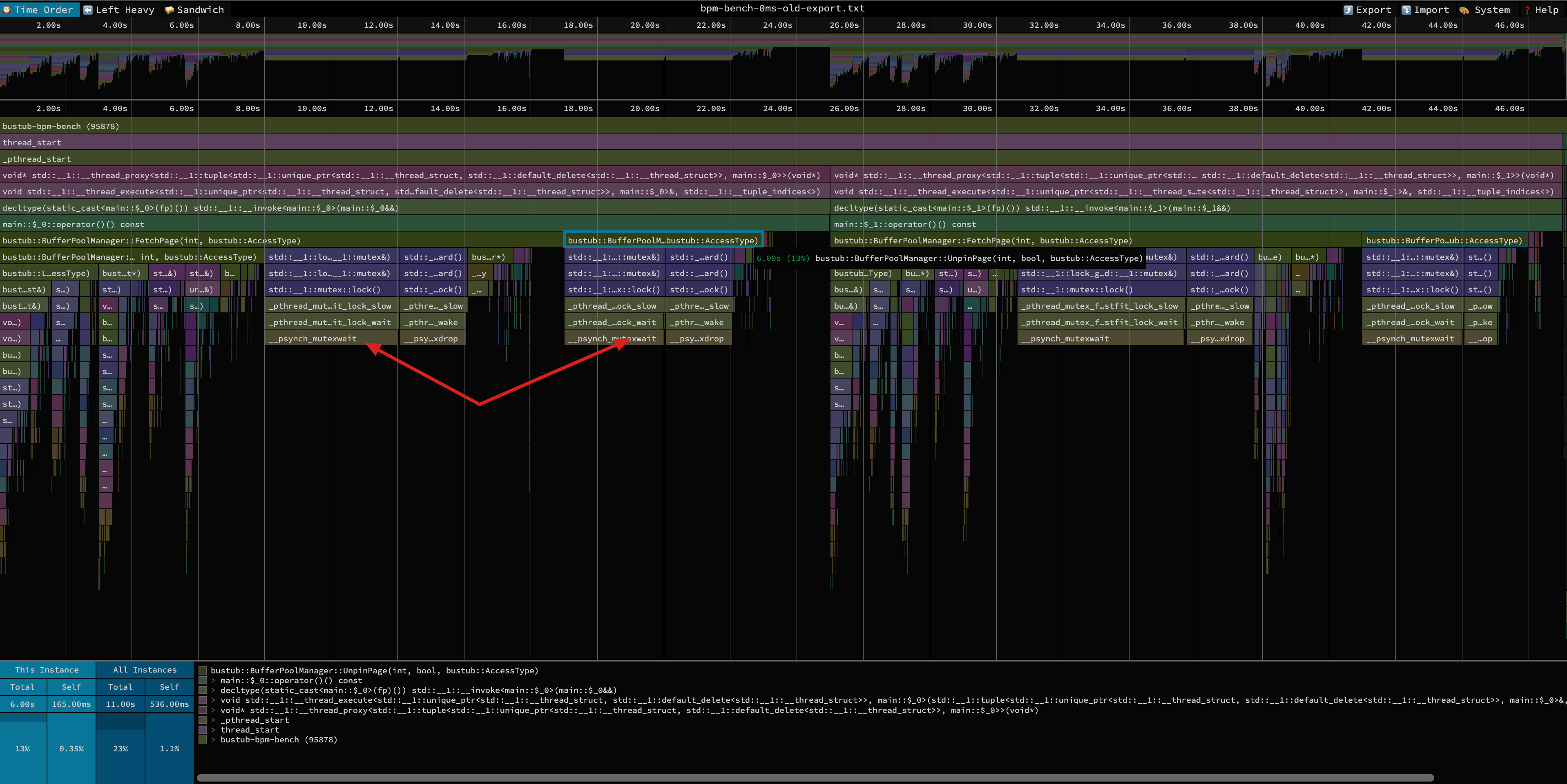
- 硬盘 0ms 读写延迟对应的 BufferPool profiling 结果和火焰图:
- 硬盘 1ms 读写延迟对应的 BufferPool profiling 结果和火焰图:
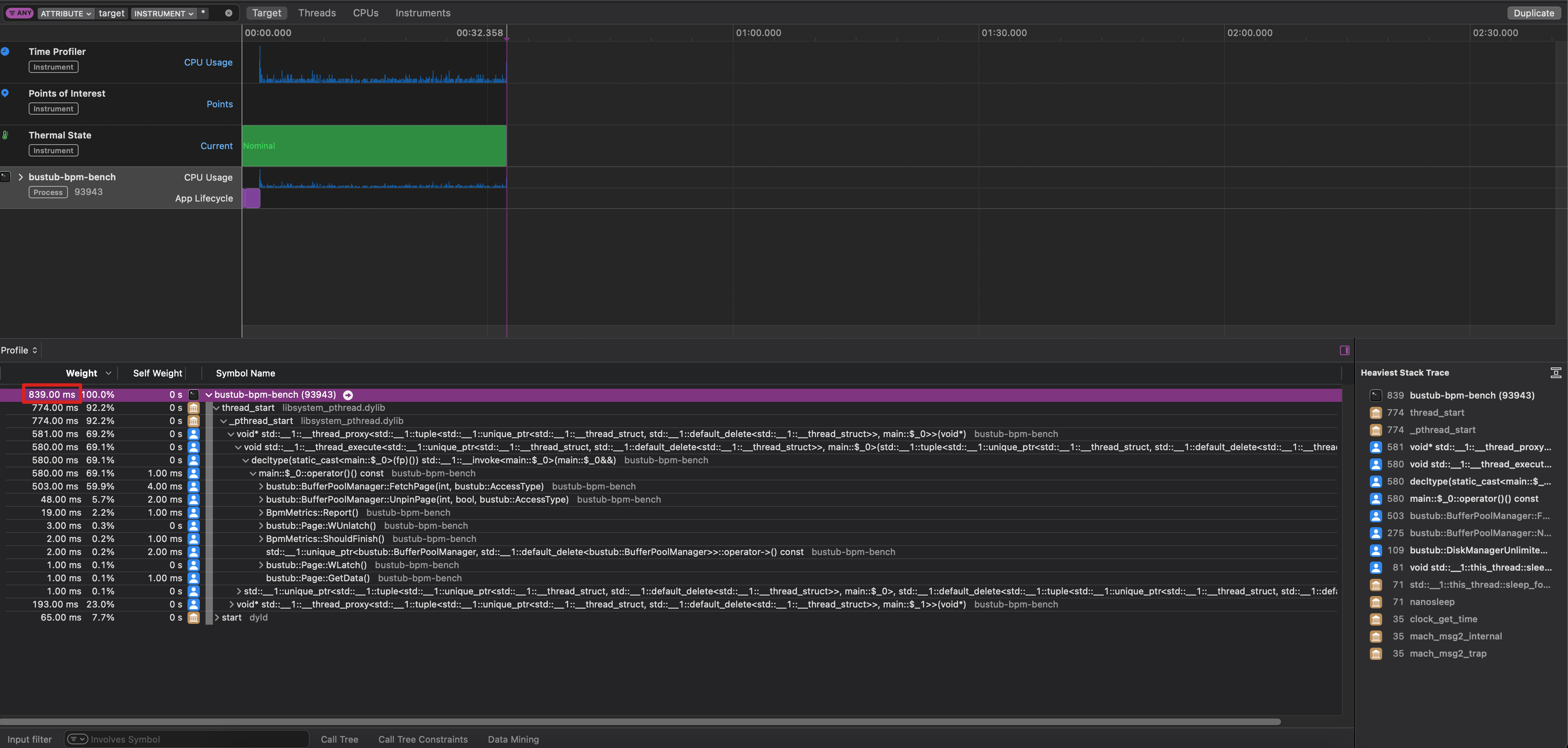
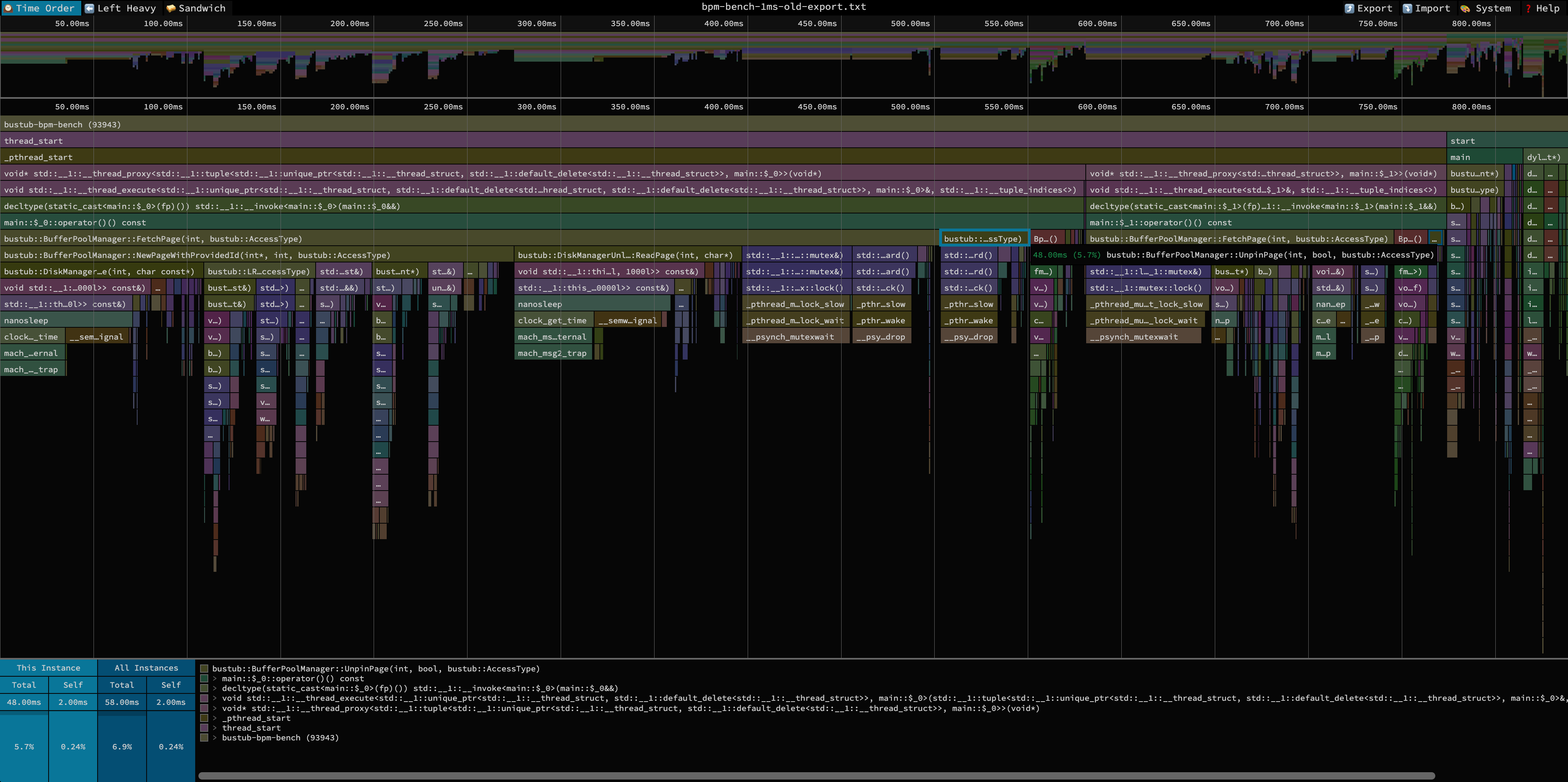
从 Profiling 结果可以看到,0ms 对应的 scan+get 线程的 CPU 占用时间为 47.75s,而 0ms 只有 839ms,这就验证了我们前面的结论——这种情况下BufferPool 的一个线程拿了大锁,阻塞在对硬盘的读写操作中,而其他线程又只能在旁边干等。
观察 0ms 对应的火焰图,除了加锁、解锁操作外没有明显的平顶,整体符合预期,因此没有必要通过更换 STL 数据结构等方式来提高性能。
优化一:异步处理硬盘读写
在目前的设计中,我们采用的是同步读写硬盘的硬盘的做法,因此会出现下图中线程 T2 拿到大锁阻塞在硬盘写操作、线程 T1 和 T3 阻塞在获取锁的情况,导致完全让出 CPU。
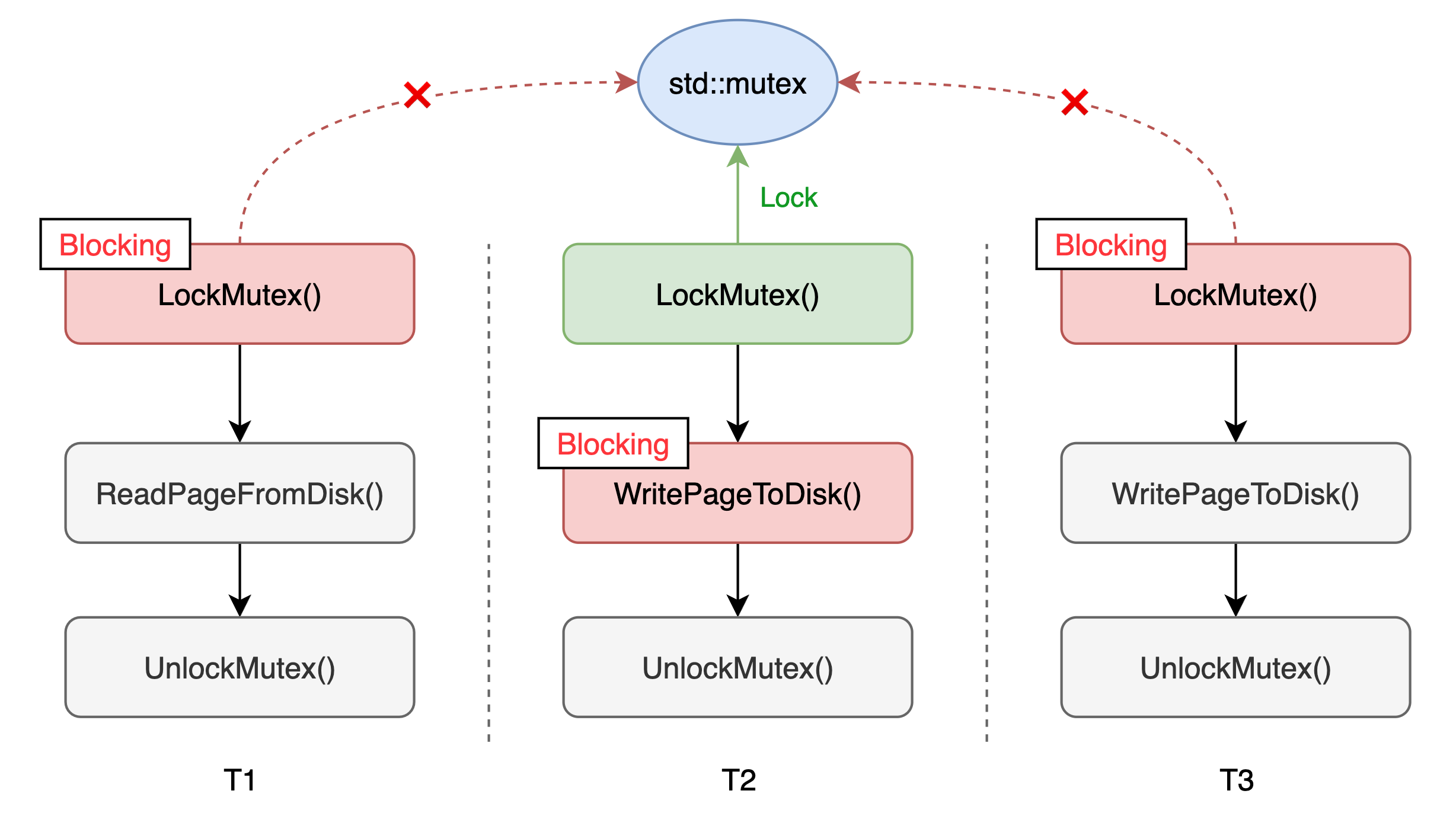
因此我们可以考虑一下,如何将硬盘的读写操作变成异步,让线程不再阻塞在这些耗时操作上面。
首先考虑硬盘读操作,读操作需要同步,因为下游在 FetchPage 之后可能会立即读取页面数据,而这个读取操作是不经过 BufferPool 的,我们无法控制。硬盘写操作可以异步执行,只要我们保证对同个页面的写操作与 WritePage 的调用顺序保持一致即可。怎么保证顺序一致?加锁!但此时我们就只需要按页面加锁(page-wise)就可以了,一个页面的硬盘读写操作不会阻塞另一个页面,大大提高了并发度。
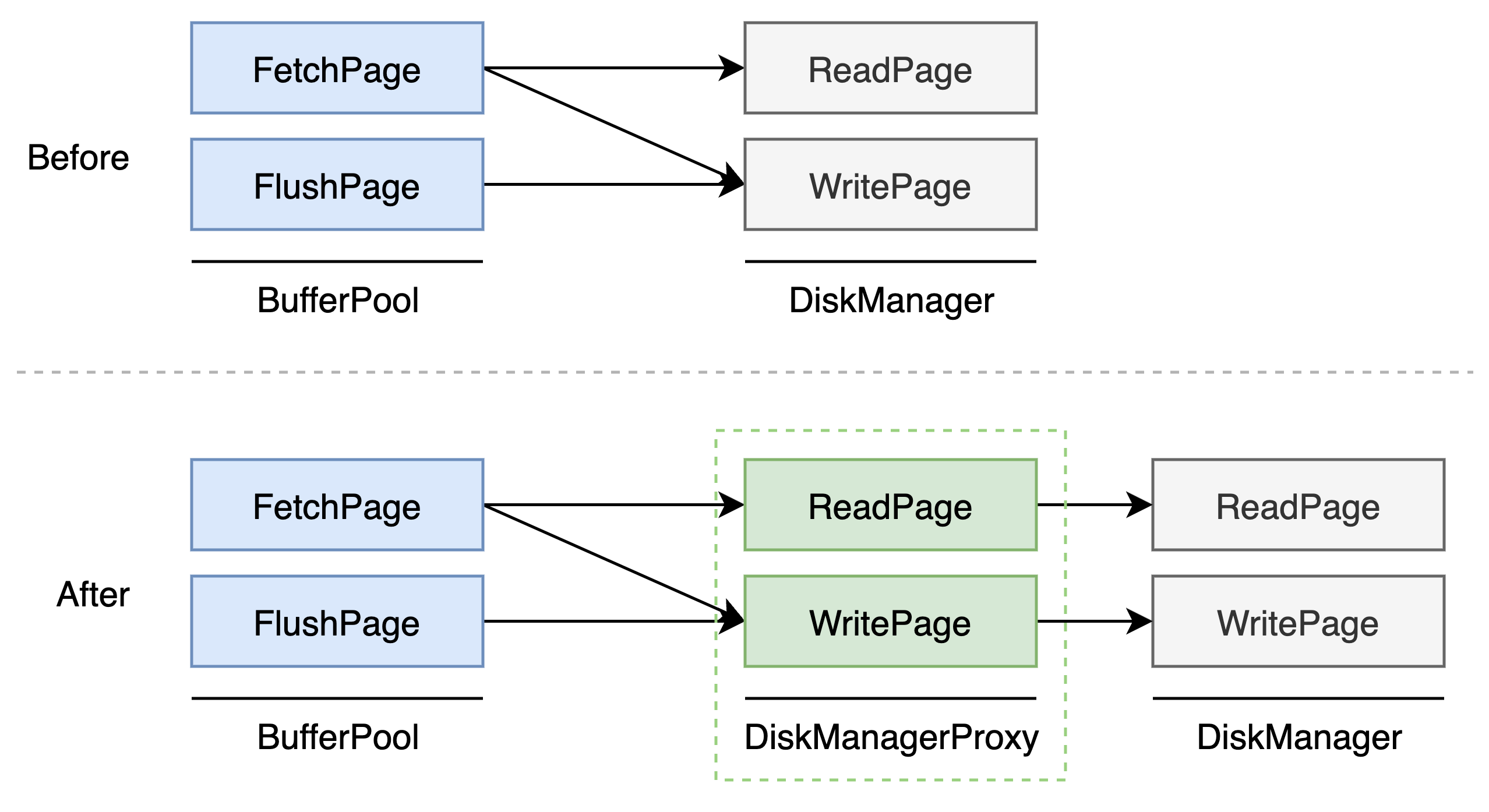
初步的想法有了,怎么设计?我们可以在 BufferPool 和 DiskManager 中间加一层 DiskManagerProxy,由 DiskManagerProxy 对外抽象硬盘的读写接口,并在内部进行读写操作的调度,如下图所示。
DiskManagerProxy 内部又如何实现呢?我们可以对每个页面维护一个写操作请求队列(DiskWriteRequestQueue),每当有一次 WritePage 调用就追加一个写请求(DiskWriteRequest),等待前面的写请求对应的线程来唤醒(通过互斥体和条件变量来协调线程)。在当前线程被唤醒后,我们需要额外创建一个线程,异步执行真正的写硬盘操作,并在写完硬盘后从请求队列中把自己 pop 掉,再唤醒等待中的写请求即可(做完 P4 的同学是不是感觉很熟悉?)
而对于读操作,我们只需要看一下 DiskWriteRequestQueue 是否为空,如果不为空,说明有写请求还未执行完成,此时我们只需要拿最后一个写请求的数据就可以了;如果为空,再执行真正的硬盘读操作。
在此基础上,我们可以注意到,读写操作的结果没有被充分利用。比如一个写操作执行完成之后,读请求进来了发现 DiskWriteRequestQueue 没有写请求,就回头读硬盘了,此时如果另外一个读请求进来了还是得读硬盘。因此我们在 DiskWriteRequestQueue 上加一块缓存,再加一个布尔值做缓存是否有效的标记。这样,写请求执行完成后发现队列里没有其他写请求了,就可以写入缓存;读请求执行完成后也可以写入缓存,后面有读请求进来就直接读缓存就可以了。
至此,我们可以得出 DiskManagerProxy 的整体框架如下:
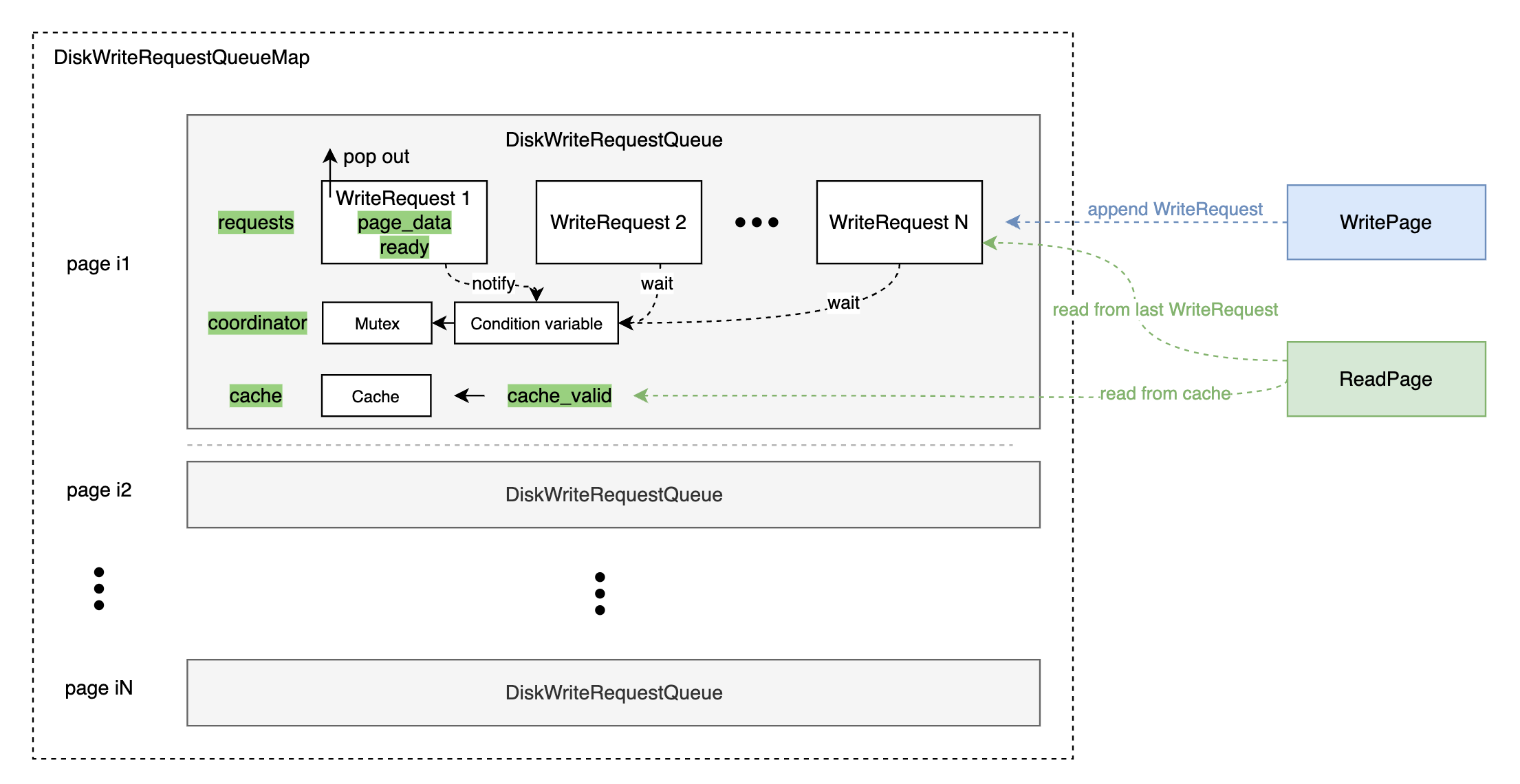
最后,我们总结一下基于 DiskManagerProxy 的硬盘读写操作(一直在想要不要把这部分写出来 🤯):
- WritePage
- 获取 page_id 对应的 DiskWriteRequestQueue 锁,构造 DiskWriteRequest 追加到写请求队列中,并将缓存置为 invalid
- 如果当前队列为空,则把自身设置为 ready
- 等待直到(其他线程将)当前写请求设置为 ready
- 新建一个线程,执行真正的 WritePage 操作,执行完成后:
- 将当前写请求 pop 出队列
- 如果队列为空,则更新缓存,并置为 valid;否则将下一个写请求置为 ready 并唤醒之
- detach 该线程
- ReadPage
- 获取 page_id 对应的 DiskWriteRequestQueue 锁,检查写请求队列是否为空,若不为空则直接拷贝最后一个写请求的页面数据
- 检查缓存是否失效,若失效则执行真正的 ReadPage 操作将页面数据加载到缓存中,并将缓存置为 valid
- 拷贝缓存中的页面数据到 BufferPool 的页面中
经过这部分优化,会发现 1ms 延迟的情况下,BufferPool 已经能达到数万 QPS 了;但 0ms 延迟的情况相比原来的实现 QPS 也会大幅降低(这也是理所当然的捏 😋)
当然,在 BufferPool 使用完成后,可能还会存在部分写请求还未执行完成,这时候需要处理完这些写请求再析构 BufferPool,不然会有 use-heap-after-free 问题,这部分就交给聪明的读者考虑啦~
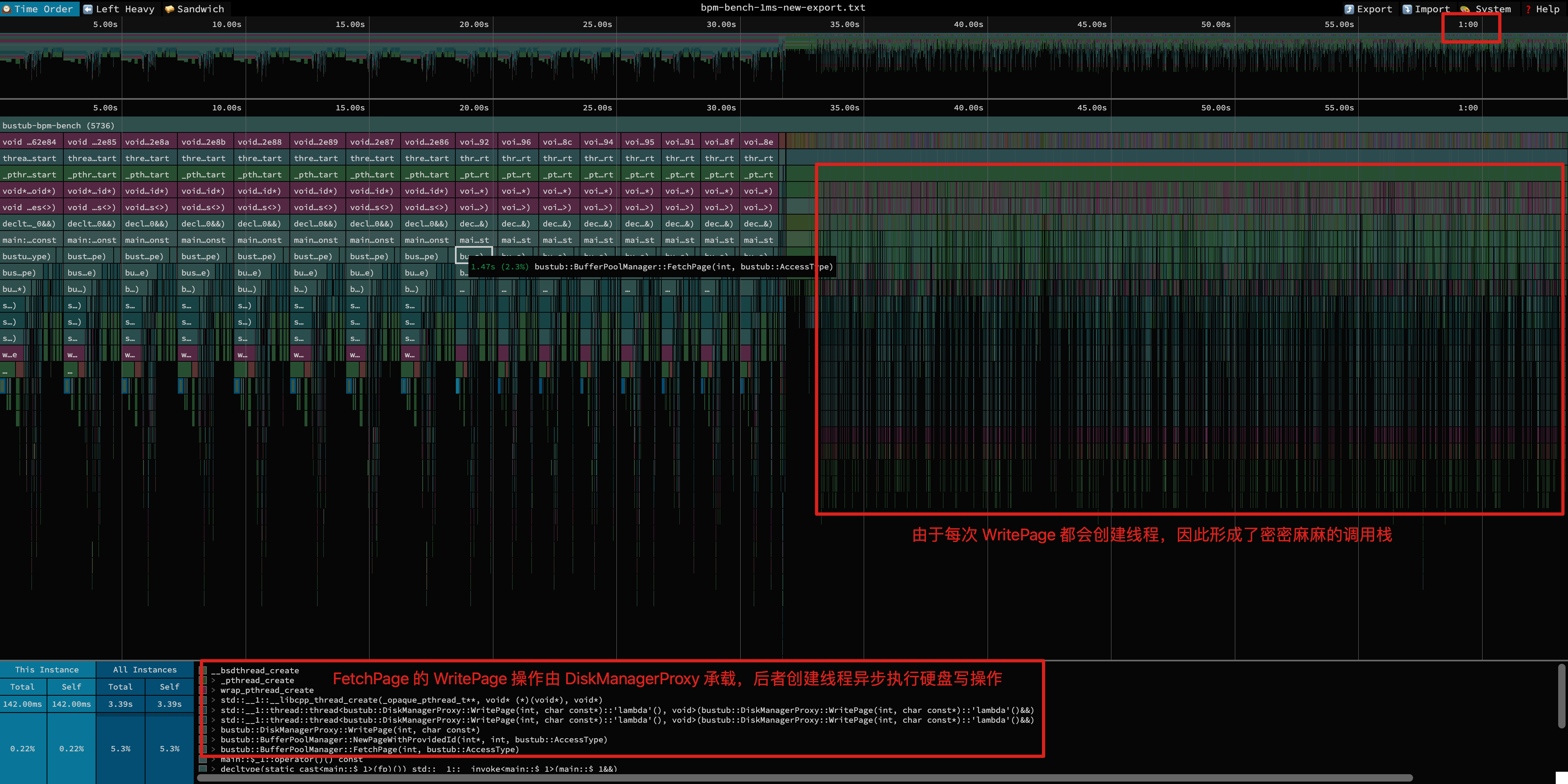
经过这一部分优化后,我们再对执行 Profiling,可以得到如下的火焰图。首先可以看到,get/scan 线程的 CPU 总占用时间重新回到了 1min 左右,符合预期。同时,由于每次写操作都会产生新的线程,所以右边会形成密密麻麻的调用栈。
优化二:针对 scan 场景调优
scan 场景的特性是,在读写第 K 个页面时,短时间内:
- 第 K-1 个页面极大概率不会被读写 -> 通过提高上一个页面的 evict 优先级优化
- 第 K+1 个页面极大概率会被读写 -> 通过预读取下一个页面优化(prefetch)
对于前者,我们在执行 RecordAccess(access_type == Scan) 操作时,如果该 frame 访问不满 K 次,可以将其放到未满 K 次访问的 frame 链表开头(而不是结尾),即让其下一个被 evict。
对于后者,由于我们目前已经是异步读取,prefetch 带来的收益并不高,反而会进一步提升实现的复杂度,因此就没有做这部分优化。
经过对比此部分优化提升可以说基本为 0,主要原因是在 bpm-bench 的 workload 下,BufferPool 的缓存命中率整体较低(之前测试过不足 < 5%),加上这一优化对缓存命中率提升也较小。
结语
本文以 CMU 15-445 P1 的性能优化过程为例,介绍了性能优化的基本思路和做法,提出 DiskManagerProxy 并发调度硬盘写操作的方法解决内存和硬盘的读写速度差异造成的性能瓶颈,稍显稚嫩,希望能帮助到需要的同学,也希望大佬们多提意见,共同进步~
